計算科学研究センター 計算情報学研究部門の天笠 俊之教授が、筑波大学2020 BEST FACULTY MEMBERに選ばれました。
表彰式は2月15日にオンラインで開催されました。

詳しくは大学ホームページをご覧ください。
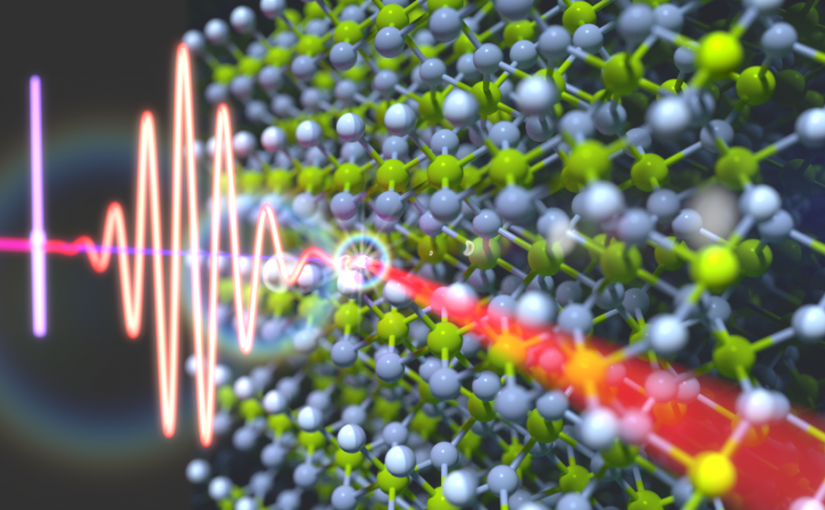
An international research team involving a researcher at Tsukuba University uses attosecond laser pulses to study electronic excitations in a dielectric crystal, which may open the way for novel computer logical elements and optical devices
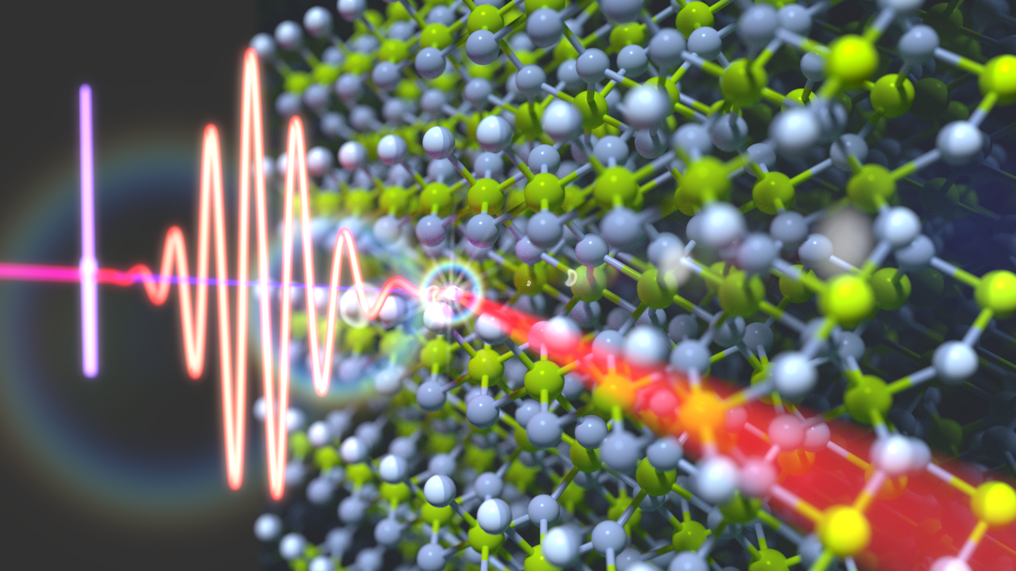
The international research team has analyzed the ultrafast electronic response inside magnesium fluoride (MgF2) crystals caused by very short laser bursts. They found that the electron behavior at attosecond timescales was similar to that seen in both atoms and solids. This work may lead to better control of the electronic activity in previously overlooked materials.
In the past decade, light-induced ultrafast electron dynamics in solids in the femtosecond (10-15 second) and the attosecond (10-18 second) regimes have been intensively studied towards the realization of future ultrafast electronics, optics, and optoelectronics. However, the fundamental understanding of many-body effects, which emerge from the interaction of many particles, in such ultrafast electron dynamics has been missing due to their complexity.
The emergence of excitons is a typical case of these many-body effects, which are among the most important quasi-particles in solids from both fundamental and technological points of view. Therefore, the development of a microscopic understanding of ultrafast exciton dynamics is an important milestone towards the science of nonequilibrium electron dynamics.
Now, a research team involving a researcher at Tsukuba University has used attosecond transient reflection spectroscopy to study core-level excitons in magnesium fluoride crystals.
“Thanks to the utilization of independent calibration experiments, we were able to achieve results that matched with theoretical simulations,” says author Professor Shunsuke Sato.
An important finding was that the exciton acted like a hybrid between an electron orbiting a single atom, and an electron delocalized over a bulk material. The researchers propose methods such as adding an external electric field or mechanical strain to the crystal to precisely control this response.
“Exploring solutions beyond classical electronics, is becoming increasingly important if we want to move beyond current technological computing limits,” Professor Sato says. “The results of our research may lead to new materials for performing computations faster and more efficiently than current systems.”
The work is published in Advanced Functional Materials as “Unravelling the intertwined atomic and bulk nature of localised excitons by attosecond spectroscopy” (DOI:10.1038/s41467-021-21345-7).
Assistant Professor SATO Shunsuke
Center for Computational Sciences, University of Tsukuba
令和3年2月15日
国立大学法人 筑波大学
半導体や絶縁体などの固体物質の中では、負の電荷を持つ電子と正の電荷を持つ正孔が互いの引力によって結びつき束縛された励起子と呼ばれる状態が生成されることがあります。本研究では、アト秒(10の18乗分の1秒)時間分解ポンプ・プローブ分光実験をフッ化マグネシウム(MgF2)単結晶に適用し、光が引き起こす励起子の超高速なダイナミクスを高い時間分解能で観測することに成功しました。
これにより、光が誘起する励起子のダイナミクスには二つの時間スケールの現象が共存していることが明らかとなりました。一つは励起子ダイナミクスを駆動する光の周期よりも長い時間スケールで生じる現象で、もう一つは光の周期よりも短い時間スケールの現象です。
微視的な数値シミュレーションにより解析を進めたところ、励起子は、長い時間スケールでみると、電子と正孔が結びついた「原子」のような振る舞いを示す一方、短い時間スケールにおいては、電子と正孔がそれぞれ空間内を自由に移動する「固体物質」的に振る舞うことが分かりました。
本研究で明らかとなった、超高速励起子ダイナミクスにおける励起子の二面性(原子的性質と固体的性質の共存)は、励起子を光制御することで物質の様々な性質を得るための、新しい方法論の可能性を示唆しています。
地球環境部門の日下博幸教授が、アメリカ気象学会(AMS)ヘルムート・ランズベルグ賞 (The Helmut E. Landsberg Award) を受賞しました。同賞は都市気象学・気候学・水文学で国際的に顕著な成果をあげたグループもしくは個人に与えられる賞で、この都市気象分野では世界最高峰の賞として知られています。 アメリカ気象学会の賞を日本人が受賞することは大変めずらしいことです。
受賞理由は以下の通りです。
国際的な研究コミュニティーによって採用された都市キャノピーモデリングの進歩と過去・現在・未来の都市気候へのダウンスケーリングへの先駆的な貢献 (For advancements in urban canopy modeling, adopted by international research communities, and pioneering contributions to downscaling past, current, and future urban climates)

AMS HP(https://www.ametsoc.org/index.cfm/ams/about-ams/ams-awards-honors/2021-awards-and-honors-recipients/)
日時:2021年2月16日(火) 8:30~18:45
会場:Zoom
計算科学研究センター 令和2年度年次報告会を行います。
発表時間は、1人15分(質疑応答、交代時間含む)
セッション1 (8:30-10:00 座長:堀江 和正)
8:30 藏増 嘉伸 (素粒子物理研究部門)
8:45 日野原 伸生 (原子核物理研究部門)
9:00 庄司 光男 (生命科学研究部門)
9:15 高橋 大介 (高性能計算システム研究部門)
9:30 宍戸 英彦 (計算情報学研究部門)
9:45 北川 博之 (計算情報学研究部門)
セッション2 (10:00-11:30 座長:西澤 宏晃)
10:00 吉江 友照 (素粒子物理研究部門)
10:15 Alexander Wagner (宇宙物理研究部門)
10:30 矢花 一浩 (量子物性研究部門)
10:45 ドアン グアン ヴァン
11:00 朴 泰祐 (高性能計算システム研究部門)
11:15 堀江 和正 (計算情報学研究部門)
セッション3 (11:30-13:00 座長:ドアン グアン ヴァン)
11:30 森 正夫 (宇宙物理研究部門)
11:45 藤田 典久 (高性能計算システム研究部門)
12:00 小泉 裕康 (量子物性研究部門)
12:15 西澤 宏晃 (生命科学研究部門)
12:30 大須賀 健 (宇宙物理研究部門)
12:45 松枝 未遠 (地球環境研究部門)
セッション4 (13:00-14:30 座長:藤田 典久)
13:00 橋本 幸男 (原子核物理研究部門)
13:15 天笠 俊之 (計算情報学研究部門)
13:30 石塚 成人 (素粒子物理研究部門)
13:45 重田 育照 (生命科学研究部門)
14:00 Tong Xiao-Min (量子物性研究部門)
14:15 塩川 浩昭 (計算情報学研究部門)
セッション5 (14:30-16:00 座長:大野 浩史)
14:30 小林 諒平 (高性能計算システム研究部門)
14:45 日下 博幸 (地球環境研究部門)
15:00 原田 隆平 (生命科学研究部門)
15:15 額田 彰 (高性能計算システム研究部門)
15:30 吉川 耕司 (宇宙物理研究部門)
15:45 中務 孝 (原子核物理研究部門)
セッション6 (16:00-17:30 座長:堀 優太)
16:00 梅村 雅之 (宇宙物理研究部門)
16:15 亀田 能成 (計算情報学研究部門)
16:30 大野 浩史 (素粒子物理研究部門)
16:45 田中 博 (地球環境研究部門)
17:00 稲垣 祐司 (生命科学研究部門)
17:15 佐藤 駿丞 (量子物性研究部門)
セッション7 (17:30-18:45 座長:佐藤 駿丞)
17:30 多田野 寛人 (高性能計算システム研究部門)
17:45 矢島 秀伸 (宇宙物理研究部門)
18:00 北原 格 (計算情報学研究部門)
18:15 堀 優太 (生命科学研究部門)
18:30 建部 修見 (高性能計算システム研究部門)
ホームページ:
https://sites.google.com/view/fpgaforhpcworkshop/
開催日時:2021年2月26日(金)13:00〜17:10
開催場所:Zoomによるオンライン開催
(ホームページから参加登録された方にID/パスワードをお知らせします)
FPGAの高性能計算(HPC)への適用はこの数年、大きく注目されており、様々な大学・研究機関において活発に研究が進んでいます。本ワークショップはタイトルにありますように、FPGAとGPUを融合した高性能計算プラットフォームに関する科学研究費による研究の成果報告会となっていますが、国内の著名なFPGA研究者による最先端の研究開発に関するトピックスが満載となっており、FPGAのHPC利用、システム構築、FPGA利用技術等、充実した内容になっています。この機会に、FPGAの先進的利用についての知見を共有し、議論をさせて頂ければ幸いです。
ワークショップはZoomによる完全オンライン形式で実施し、どなたでも参加頂けます。講演は全て日本語で行われます。参加費は無料ですが、オンライン接続情報の共有のため参加登録が必須となります。詳細は上記のホームページをご覧ください。多くの皆さんの参加をお待ちしております。
・「FPGAの高性能計算への適用」朴 泰祐 (筑波大学)
・「CHARM: GPU・FPGA複合演算アクセラレーション」小林 諒平 (筑波大学)
・「OpenCLとFPGA間通信機構を用いた並列計算の実現」藤田 典久 (筑波大学)
・「FPGAクラスタ試作システム ESSPER とそのFPGA間通信機構」佐野 健太郎 (理化学研究所)
・「マルチFPGAのためのソフトウェア支援型データ通信機構」宮島 敬明 (理化学研究所)
・「HPC向け大規模FPGAクラスタのためのネットワークシステム」上野 知洋 (理化学研究所)
・招待講演「 様々な演算加速機構へのオフロードを記述するタスク並列モデル」 佐藤 三久 (理化学研究所)
・「FPGAによる変動精度演算オフローディングの実現」塙 敏博 (東京大学)
・「FPGA管理による大容量ストレージシステム」山口 佳樹 (筑波大学)
・招待講演「 Edge computingとFPGA 」工藤 知宏 (東京大学)
・「PYNQなクラスタ」天野 英晴 (慶應義塾大学)
1. 公募する職名・人数
助教(任期付)・1名
2. 所属部門、講座、研究室等
計算科学研究センター量子物性研究部門
3. 専門分野、仕事の内容
当研究部門では、2021年4月より新たに教授(大谷実)が着任します。大谷研究室では、エネルギー材料の第一原理計算に加えて、固体表面、固体・固体界面や固体・液体界面を第一原理計算で扱うための方法論の開発も行います。これらの研究を通して、実験家との共同研究を意欲的に進めていただける方を希望します。
4. 着任時期
決定後できるだけ早い時期
5. 任期
2022年3月31日まで (更新可・最長2025年3月31日まで)
6. 応募資格
博士の学位を有する者
7. 提出書類
以下の(1)-(6)の内容を含む電子ファイルを提出してください。
(1)履歴書(写真添付)
(2)業績リスト(査読論文とその他を区別すること)
(3)これまでの研究の概要(A4用紙1枚程度)
(4)着任後の研究に関する抱負(A4用紙1枚程度)
(5)外部資金の獲得状況
(6)照会者2名の連絡先、もしくは推薦書2通
(7)主要論文別刷5編(うち4編以上は最近5年以内のもの)
8. 応募締切
2021年4月30日(金)必着
9. 問い合わせ先
筑波大学計算科学研究センター量子物性研究部門主任 矢花一浩
Tel: 029-853-4202
Email: yabana[at]nucl.ph.tsukuba.ac.jp ([at]を@に置き換える)
10. 応募書類送付先
提出書類は、以下のAかBのどちらかの方法でお送りください。
A . 提出書類のpdfファイルをUSBメモリに入れて、封筒に「応募書類在中」と明記し、以下まで簡易書留で郵送してください。USBメモリは返却いたしません。
〒305-8577
茨城県つくば市天王台1−1−1
筑波大学計算科学研究センター
矢花一浩
B . 提出書類の(1)-(6)を一つのPDFファイルにまとめパスワードをかけ、(7)の各論文のPDFファイルとともに電子メールの添付ファイルとして、下記のアドレス
koubo-condmat[at]ccs.tsukuba.ac.jp ([at]を@に置き換える)
にお送りください。PDFファイルのパスワードは、別途下記のアドレス
yabana[at]nucl.ph.tsukuba.ac.jp ([at]を@に置き換える)
にお送りください。ファイルサイズの合計が10MBを超える場合は、問い合わせ先に連絡してください。メールの件名は、「量子物性研究部門応募書類」としてください。メール送信後、2日以内に受領確認のメールが届かない場合は、問い合わせ先に連絡してください。
推薦書は、作成者が下記のアドレス
koubo-condmat[at]ccs.tsukuba.ac.jp ([at]を@に置き換える)
に直接電子メールの添付ファイルとして送付してください。メールの件名は、「〇〇氏推薦書」または「Recommendation-Name」(Nameは応募者の氏名)としてください。
11.その他
令和3年1月26日
国立大学法人 東京大学
国立大学法人 筑波大学
公立大学法人 尾道市立大学
大学共同利用機関法人 自然科学研究機構 国立天文台
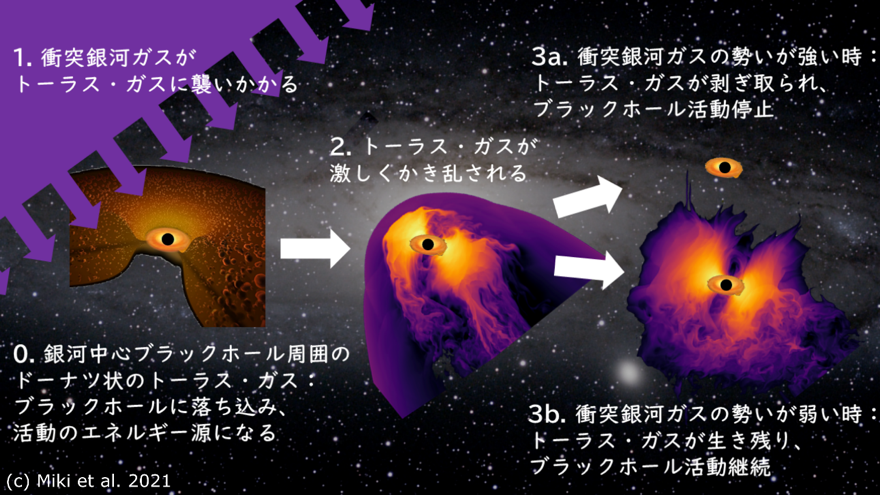
◆銀河中心の大質量ブラックホールの活動性の活性化・不活性化の起源を、銀河の衝突現象と結びつけることで、世界で初めて解明しました。
◆小さな銀河が大きな銀河に衝突してブラックホール周辺の物質を剥ぎ取ってしまうことで、ブラックホールの活動を停止させる場合もある事を証明しました。
◆本研究はブラックホールと銀河の相互の進化解明のマイルストーンとなることが期待されます。
宇宙には太陽の質量の10万倍を超える大質量ブラックホール(注1)があまねく存在しますが、そのごく一部は落ち込む物質をエネルギー源にして明るく輝き激しく活動しているものの、ほとんどは銀河の中心でひっそりと佇んでいます。こうしたブラックホールの活動と休眠の間の状態変化をつかさどるメカニズムが未解明である中、東京大学情報基盤センターの三木洋平助教、筑波大学計算科学研究センターの森正夫准教授、尾道市立大学経済情報学部/国立天文台の川口俊宏准教授の研究グループは、Oakforest-PACS(オークフォレストパックス、注2)等のスーパーコンピュータを駆使し、銀河衝突と銀河中心ブラックホールの活動性の謎を世界で初めて明らかにしました。
銀河中心ブラックホールは、これまで銀河衝突により激しく活動すると信じられてきました。衝突によって銀河円盤の物質が中心に落下し、ブラックホールに落ち込むことでその活動にスイッチが入ります。しかし銀河衝突が中心で起こった場合、事態は全く異なります。矢が正鵠を射ぬくがごとく、中心に衝突した銀河がブラックホール周辺のガスを持ち去ってしまい、エネルギー源を失ったブラックホールは活動を停止し静かに眠りにつくのです(図1、図2)。
本研究が明らかにしたブラックホール活動性の休眠メカニズムは、最近の観測によって見つかった、銀河中心ブラックホールの活動が急停止した兆候を示す新種族の天体群との関連もうかがうことができ、天文学最大の謎の一つである、銀河の進化に伴う銀河中心ブラックホールの形成解明へのマイルストーンとなることが期待されます。

東京大学大学院新領域創成科学研究科物質系専攻の佐々木裕次教授、産業技術総合研究所 先端オペランド計測技術オープンイノベーションラボラトリバイオ分子動態チーム 三尾和弘 ラボチーム長、藤村章子特別研究員、筑波大学計算科学研究センター生命科学研究部門 重田育照教授らの研究グループは、熱や痛みの伝達を司る TRP チャネルの 1 分子内部運動を、マイクロ秒オーダーで実時間計測することに世界で初めて成功し、 この研究成果が the Journal of Physical Chemistry の表紙に採用されました。
the Journal of Physical Chemistry
(研究成果についてプレスリリース「『熱』や『痛み』を感じるタンパク質の小さい動きを高速キャッチ! -体に優しい鎮痛薬開発のための新たな創薬指針の提案へ- 」をどうぞ)
2021年度筑波大学計算科学研究センター「学際共同利用」プログラムの公募が始まりました。
詳しくは学際共同利用のページをご覧ください。
奮ってのご応募をお持ち申し上げます。
公募締切:2021年1月24日(金)
2021年1月19日、一般財団法人高度情報科学技術研究機構(RIST)の主催による、COVID-19に関するセミナーが開催されます。
発生から1年経ってもなお世界的に猛威を振るっているCOVID-19に対して、HPCIは今年4月から「新型コロナウイルス感染症対応HPCI臨時公募課題」の募集行っており、計算科学研究センターのCygnus、JCAHPCのOakforest-PACSも利用されています。今回、この取り組みを広く知っていただくために、HPCIを利用した研究について紹介するとともに、スーパーコンピュータの社会貢献と今後の可能性について一般の方向けに座談会形式のセミナーが開催されることとなりました。
研究者、計算科学に興味のある方、学生まで幅広い方の参加をお待ちしております。
セミナー特設ページ(外部リンク)
【開催日】 2021年1月19日(火)13:30-15:40
【開催形式】Webexによるオンライン開催
【主 催】一般財団法人高度情報科学技術研究機構(RIST)
【参加費】無料 (事前にお申し込みが必要です。)
【プログラム】
<座談会>
「社会を支えるスーパーコンピュータ~HPCI fights against COVID-19~」(動画放映)
<講演>
・Covid-19関連タンパクに対するインシリコリポジショニング
(筑波大学計算科学研究センター 重田 育照)
・分子動力学シミュレーションで見るCOVID-19ウイルスのRNAポリメラーゼとその阻害薬
(分子科学研究所 奥村 久士)
・Nanoporeシーケンサと深層学習を用いた新型コロナウィルスRNA修飾の解析
(東京大学先端科学技術研究センター 上田 宏生)
※開催内容は変更となる場合があります。
【申込方法】WEBページ(https://fugaku100kei.jp/events/20210119/)より申込み
【申込締切】1月15日(金)
【問合せ】
一般財団法人高度情報科学技術研究機構
神戸センター HPCIオープンセミナー事務局 (event[at]hpci-office.jp [at]→@)
量子物性研究部門 小泉 裕康 准教授の論文が、EPL’s top 10 most discussed and shared research from 2020 に選ばれました。
これは物理学の全ての分野をカバーする学術誌 EPL に今年掲載された論文のうち、ニュース、ブログ、SNSなどを通じて最も話題となった論文をランキングしたもので、小泉准教授の成果は幅広いメディアに取り上げられ、第1位にランクインしています。
論文発表時の日本語版プレスリリース:「なぜ、超伝導電流は電気抵抗なしで消えるのか? 〜磁場中での超伝導-常伝導相転移を説明する新理論〜」 (2020.8.22)

2021年1月29日(金) 13:30~17:30 web講習会 (要事前申込)
GENESIS (GENeralized-Ensemble SImulation System)は理化学研究所で開発されている分子動力学(MD)計算ソフトウェアです。特に生体高分子(タンパク質、核酸、糖鎖など)を対象としています。また独自の高速化、並列化手法を持つため、効率の良い計算手法が利用でき、富岳などのスーパーコンピュータからGPU計算機、インテル計算機まで対応しています。今回の講習会では、GENESISによる生体高分子のMDにご興味がある方を対象に、筑波大学計算科学研究センターのCygnusを利用して実際のシミュレーションに触れていただきながら、講習を行います。初めてGENESISを利用される方の参加も歓迎いたします。
講習会終了後、フリーディスカッションの時間を設けております。GENESISの利用方法などにご興味がある方は、この機会にぜひ、ご参加ください。
関連リンク:HPCI セミナー情報ページ
| 日時 | 2021年1月29日(金)13:30~17:30 (13:00接続開始) |
| 場所 |
筑波大学計算科学研究センターワークショップ室、または、web会議システム BlueJeansを使用したオンライン参加
*講師はオンラインでの参加になります。 *新型コロナウィルスの影響により、講習会当日にワークショップ室を使わず、オンラインのみの開催になる場合もございます。あらかじめご了承ください。 |
| 受講資格 |
|
| 参加費 | 無料 |
| 定員 | 12名程度(先着順) |
| 受講の際の注意事項 |
以下について事前にご確認ください。
→ 当日は、CygnusへSSH接続するためのノートパソコンをお持ちください。
→ 事前に接続の可否をご確認ください。
→ オンラインのみで参加される方はBlueJeansアプリを用いた接続をお願いします。事前に接続の可否をご確認ください。
→ ハンズオンでは、Linuxを使用します。基本的なコマンドの使い方(cat、ls、cd、pwd、cp、tar)を事前にご確認ください。
*Linux初心者向けの簡単な資料も用意しています。受講者の方には、他の資料と同様に配布いたします。
→ ハンズオンでは、簡単にテキストファイルの編集を行っていただきます。テキストエディタとして、viあるいはEmacsを使用していただきますので、基本的な使い方を事前にご確認ください。
|
2021年1月29日
| 13:30-13:45 | 事務局からのお知らせとBlueJeansの機能説明 |
| 13:45-14:20 | GENESISの概要 |
| 14:20-14:50 | Cygnusの紹介、GENESISのCygnusでのジョブ実行方法 |
| 14:50-15:10 | <休憩> |
| 15:10-16:30 | GENESISでのMD計算ハンズオン、もしくはデモ |
| 16:30-17:30 | フリーディスカッション |
岩橋千草氏(理化学研究所計算科学研究センター)
Jaewoon Jung氏(理化学研究所計算科学研究センター)
松岳大輔氏(高度情報科学技術研究機構)
| 主催: | 筑波大学計算科学研究センター |
| 共催: | 一般財団法人 高度情報科学技術研究機構 |
本講習会で使用するテキストは、当日に配布いたします。
申込フォームからお申し込みください。メールでのお申し込みは受け付けておりません。
申込締切は 2021年1月19日(火) 17:00 とさせていただきます。
定員に達しましたら、お申し込みを締め切らせていただきます。
hpci-workshop[-at-]hpci-office.jp ([-at-]は@にしてください)までお問い合わせください。
-体に優しい鎮痛薬開発のための新たな創薬指針の提案へ-
東京大学大学院新領域創成科学研究科物質系専攻の佐々木裕次教授、産業技術総合研究所先端オペランド計測技術オープンイノベーションラボラトリバイオ分子動態チーム 三尾和弘ラボチーム長、藤村章子特別研究員、筑波大学計算科学研究センター生命科学研究部門 重田育照教授らの研究グループは、熱や痛みの伝達を司るTRPチャネル(注1)の1分子内部運動を、マイクロ秒オーダーで実時間計測することに世界で初めて成功しました。
ヒト及び多様な動物種の複数の感覚刺激の応答に関与することで知られるTRPチャネルは、4つのサブユニット(注2)から構成され、細胞膜を24回貫通する分子です。最近、詳細な分子構造が決定され、研究が一層加速され注目を集めています。TRPチャネルを活性化させるカプサイシンを添加した実験では、チャネルを開けてイオンを流す動きは、右回りのねじれ運動を伴い、またチャネルを阻害する薬剤を添加した実験では、それと逆向きに左回りのねじれ運動を検出しました。さらにカプサイシンが反応しない変異体TRPチャネルを使った実験では、阻害する薬剤を加えた時と同様にチャネルの運動を抑える左回りのねじれ運動が検出されました。このようにさまざまな条件下でリアルタイムにダイナミックな動きを検出することに成功しました。また、これらの動きがすべて数十pm2/msという極めて小さい拡散定数(注3)で動いていることも判明しました。
本研究グループが用いた計測法は「X線1分子追跡法(Diffracted X-ray Tracking: DXT)」(注4)と呼ばれるもので、金ナノ結晶でラベルされた部位における分子内部動態を1分子動画として検出します。この実験は兵庫県西播磨にある大型放射光施設SPring-8の BL40XU(注5)で行われました。DXTは従来の分子構造決定や反応ポケットの構造解析だけからは得られない、分子の動きに着目した新しい創薬技術の開発への貢献が大いに期待されます。
この成果の詳細は物理化学領域において長い歴史のある国際誌Journal of Physical Chemistryに掲載され、本研究のイメージ図が表紙に採用される予定です。なお、雑誌掲載に先立ち、同誌Webサイトにて、2020年12月9日にオンライン公開されました。
2021年1月28日(木) 13:30~17:30 web講習会
SALMONは、光と物質の相互作用で起こる多様なナノスケールの電子ダイナミクスに対して第一原理計算を行うオープンソース計算プログラムです。 計算は時間依存密度汎関数理論に基づいており、ノルム保存擬ポテンシャルを含む時間依存コーンシャム方程式を実時間・実空間で解きます。光電磁場の伝搬を記述することも可能です。今回の講習会は、SALMONを用いて光と物質の相互作用を計算することに興味のある方を対象に、SALMONの背景となる基礎理論と計算法の簡単な説明を行ったのち、大阪大学サイバーメディアセンターの全国共同利用大規模並列計算システムOCTOPUSを用いて実際にSALMONを用いた実習を行います。理論の研究者だけではなく、実験研究者や企業研究者、大学院生のご参加を歓迎いたします。
詳細および受講申し込みはこちら (外部リンク)
| 日時 | 2021年1月28日(木)13:30~17:30 (13:00接続開始) |
| 場所 |
web会議システム Zoomを使用したWeb講習会
|
| 受講資格 |
|
| 参加費 | 無料 |
| 定員 | 10名程度(先着順) |
| 受講の際の注意事項 |
以下について事前にご確認ください。
事前に接続の可否をご確認ください。
Zoomアプリを用いた接続をお願いします。事前に接続の可否をご確認ください。
ハンズオンでは、Linuxを使用します。基本的なコマンドの使い方(cat、ls、cd、pwd、cp、tar)を事前にご確認ください。
*Linux初心者向けの簡単な資料も用意しています。受講者の方には、他の資料と同様に配布いたします。
ハンズオンでは、簡単にテキストファイルの編集を行っていただきます。テキストエディタとして、viあるいはEmacsを使用していただきますので、基本的な使い方を事前にご確認ください。
|
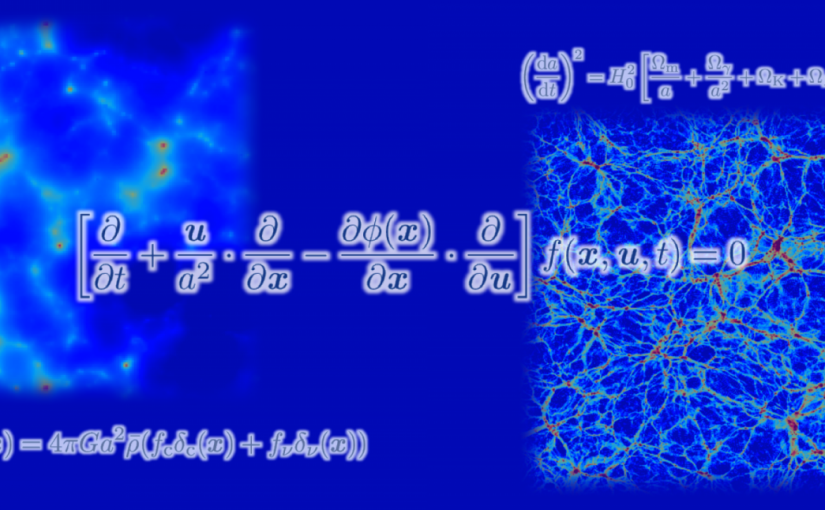
Researchers led by the University of Tsukuba devise a new approach to show how ghost-like neutrinos helped shape the Universe
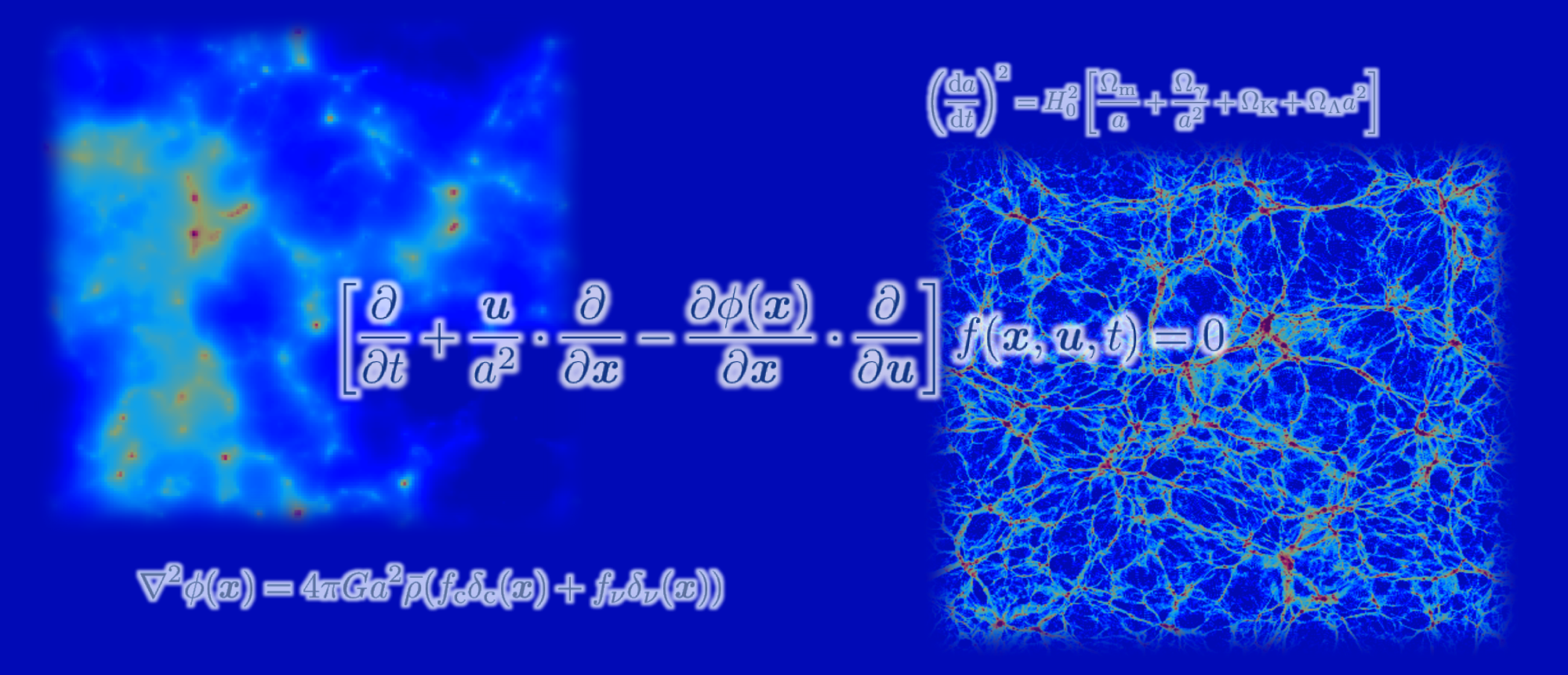
Tsukuba, Japan – Computer simulations have struggled to capture the impact of elusive particles called neutrinos on the formation and growth of the large-scale structure of the Universe. But now, a research team from Japan has developed a method that overcomes this hurdle.
In a study published this month in The Astrophysical Journal, researchers led by the University of Tsukuba present simulations that accurately depict the role of neutrinos in the evolution of the Universe.
Why are these simulations important? One key reason is that they can set constraints on a currently unknown quantity: the neutrino mass. If this quantity is set to a particular value in the simulations and the simulation results differ from observations, that value can be ruled out. However, the constraints can be trusted only if the simulations are accurate, which was not guaranteed in previous work. The team behind this latest research aimed to address this limitation.
“Earlier simulations used certain approximations that might not be valid,” says lead author of the study Lecturer Kohji Yoshikawa. “In our work, we avoided these approximations by employing a technique that accurately represents the velocity distribution function of the neutrinos and follows its time evolution.”
To do this, the research team directly solved a system of equations known as the Vlasov–Poisson equations, which describe how particles move in the Universe. They then carried out simulations for different values of the neutrino mass and systemically examined the effects of neutrinos on the large-scale structure of the Universe.
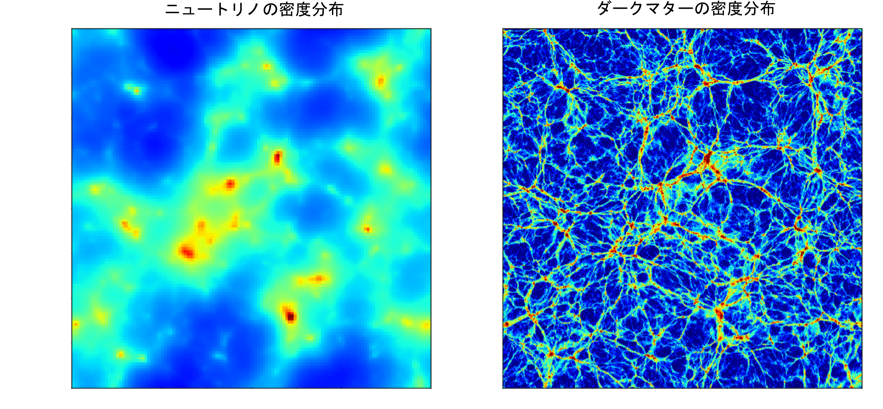
The simulation results demonstrate, for example, that neutrinos suppress the clustering of dark matter—the ‘missing’ mass in the Universe—and in turn galaxies. They also show that neutrino-rich regions are strongly correlated with massive galaxy clusters and that the effective temperature of the neutrinos varies substantially depending on the neutrino mass.
“Overall, our findings suggest that neutrinos considerably affect the large-scale structure formation, and that our simulations provide an accurate account for the important effect of neutrinos,” explains Lecturer Yoshikawa. “It is also reassuring that our new results are consistent with those from entirely different simulation approaches.”
This work represents a milestone in simulating the Universe and paves the way for further exploration of how neutrinos influence the formation and growth of the large-scale structure. For instance, the new simulation approach could be used to study the dynamics of neutrinos and unconventional types of dark matter. Ultimately, it might lead to a determination of the neutrino mass.
The article, “Cosmological Vlasov–Poisson Simulations of Structure Formation with Relic Neutrinos: Nonlinear Clustering and the Neutrino Mass,” was published in The Astrophysical Journal at DOI: 10.3847/1538-4357/abbd46
Assistant Professor YOSHIKAWA Kohji
Center for Computational Sciences, University of Tsukuba
物質を構成する基本的な素粒子の一つであるニュートリノは我々の宇宙に大量に存在し、わずかながら質量を持つことが知られています。しかし、その質量は、地上の素粒子実験などでは測定が困難で、未解明の謎として残っています。一方、宇宙における天体や物質の分布(大規模構造)の詳細な観測からニュートリノの質量を測定できることが近年の宇宙進化の理論によって示され、大型観測プロジェクトが世界中で計画されています。
理論的には、精緻な数値シミュレーションにより宇宙の大規模構造を詳細に再現することが必要ですが、そのためには、多次元空間中での素粒子の集団的な運動を記述する「ブラソフ方程式」を解かなくてはなりません。この難解な方程式を解くためには膨大な計算時間やコンピュータの記憶容量が必要なため、これまではニュートリノの分布を仮想的な粒子の分布に置き換え、近似的な解を得ることしかできませんでした。しかしこの方法では、再現された宇宙の物質分布に人工的な数値ノイズが混入するという大きな問題があります。
本研究では、筑波大学と東京大学が新たに開発したブラソフ方程式の高精度計算手法と、国内を代表するスーパーコンピュータを組み合わせることによって、ブラソフ方程式を直接解き、宇宙を高速で飛び交うニュートリノの6次元数値シミュレーションを行うことに、世界で初めて成功しました。これにより、ニュートリノの集団的な運動の様子を正確に調べることができるようになり、ニュートリノの質量を正確に測定するための理論モデルの構築が可能となりました。
論文はこちら


国立大学共同利用・共同研究拠点協議会が2020年4月より動画配信している「知の拠点【すぐわかアカデミア。】」の No.15 として、筑波大学計算科学研究センターの動画が公開されました。
高性能計算システム研究部門の藤田助教協力のもと、スーパーコンピュータCygnusやCygnusを使った研究などを8分弱の動画で紹介しています。