エクサフロップスとその先に向かう最先端基盤技術開発
室長 朴 泰祐 教授
並列型スーパーコンピュータシステムのピーク演算性能は、ノード(プロセッサ)性能×ノード数によって表されます。これまでノード数を増やすことで性能向上を追求してきましたが、電力消費や故障率などの問題があり、単純なノード数増強による性能向上は限界に近づきつつあります。世界最高性能スーパーコンピュータはエクサスケールに達しつつありますが、これを達成しさらにその先の性能を実現するには、数十万〜数百万ノードにおける耐故障技術を確立することと、ノード単体の演算性能を100TFLOPSレベルまで引き上げる必要があります。後者を達成するためには演算加速機構が有望で、これによりシミュレーションのステップあたりの時間短縮(strong-scaling)が可能になると考えられます。
次世代計算システム研究開発室では、多重複合型演算加速(MHAS: Multi-Hybrid Accelerated Supercomputing)コンセプトに基づく次世代の高性能計算システムの基盤技術研究を行なっています。ここで中心的役割を果たすのはFPGA (Field Programmable Gate Array)で、このデバイスの演算と通信の飛躍的な高性能化を背景に、これを演算・通信の融合に適用します。従来のCPUとGPUの組み合わせだけでは十分な演算加速が行えなかったアプリケーションに対し、FPGAを補完的に用いることで理想的な演算加速を行うというコンセプトの下、2017年度よりその実証実験のためのミニクラスタである PPX (Pre-PACS-X)を開発・拡張し、その実用化システムとしてPACSシリーズの第10世代スーパーコンピュータであるCygnusを開発、2019年度より運用を開始しました。ここで開発されている主な技術をご紹介します。
FPGAとGPUを協調利用するアプリケーションの開発
高性能計算システム研究部門と宇宙物理研究部門の協働により、宇宙初期天体形成シミュレーションにおける輻射輸送問題を含むARGOTコードについて、GPUとFPGAが密結合したプラットフォームで高速に動作するようにコードを開発しています。ARGOTコード全体を1ノードのGPU+FPGAの協調計算で実行できるようになり、GPUのみの計算に比べ最大17倍の高速化を達成しました。さらにGPUとFPGAの間でCPUを介さない高速通信を行うDMAエンジンも開発しています。さらに、地球環境研究部門・量子物性研究部門などとの共同研究を通じ、センターで独自開発されている応用コードのGPU/FPGA連携高速化も順次進めています。
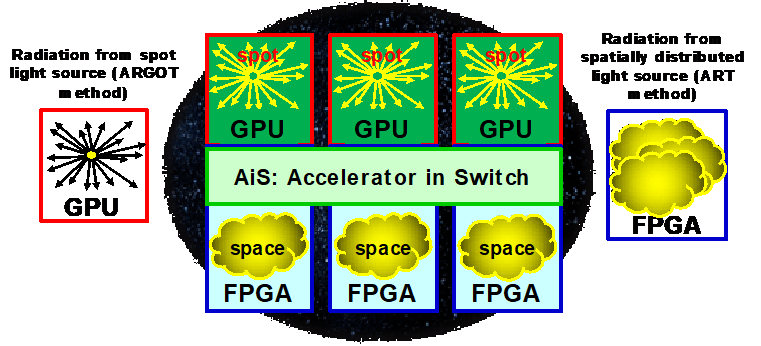
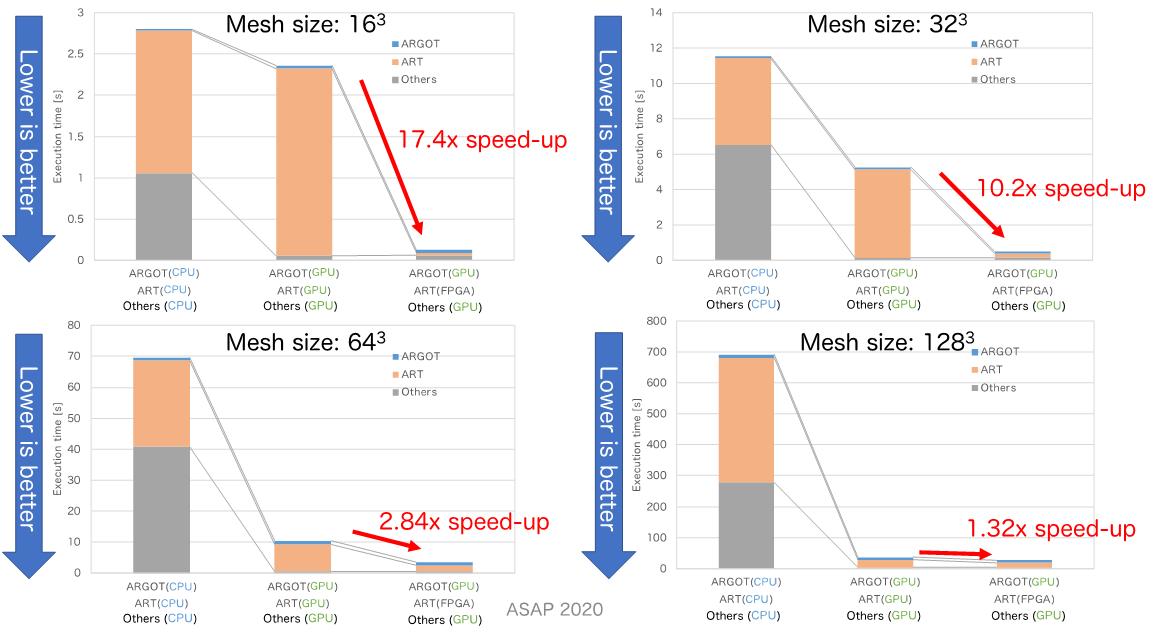
図:宇宙初期天体形成シミュレーションにおけるGPU+FPGAの協調計算の性能
FPGA間接続高速光ネットワークのためのOpenCLインターフェイス
100Gbpsの物理性能を持つFPGA間ネットワークをユーザレベルから容易に用いる通信フレームワークCIRCUS (Communication Integrated Reconfigurable CompUting System)を開発し、Cygnusスーパーコンピュータ上で90Gbpsの高性能通信を達成しています(理論ピーク性能100Gbpsの90%)。これをARGOTコードのFPGAオフロード部分に適用し、並列FPGA処理がスムーズに行えることも確認しています。
GPUとFPGAの統一プログラミング環境
理化学研究所計算科学研究センター及び米国Oak Ridge National Laboratoryと共同で、MHOATと呼ぶOpenACCトランスレータを開発しています。これにより、FPGAとGPUの連携プログラミングをOpenACCのみで実現可能になります。MHASのコンセプトを簡便なプログラミング環境で利用可能とすることで幅広いアプリケーションへの適用を目指します。
(最終更新日:2021.5.25)