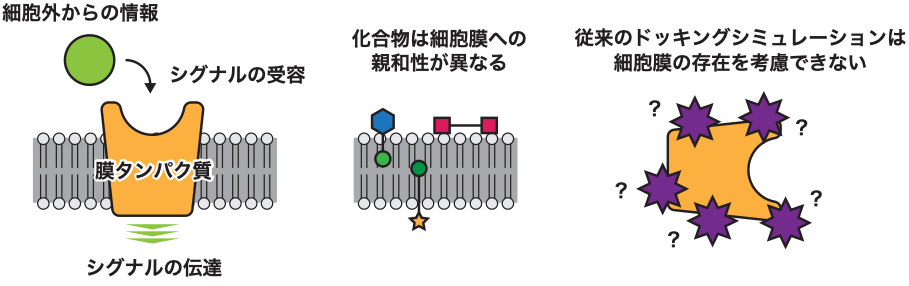
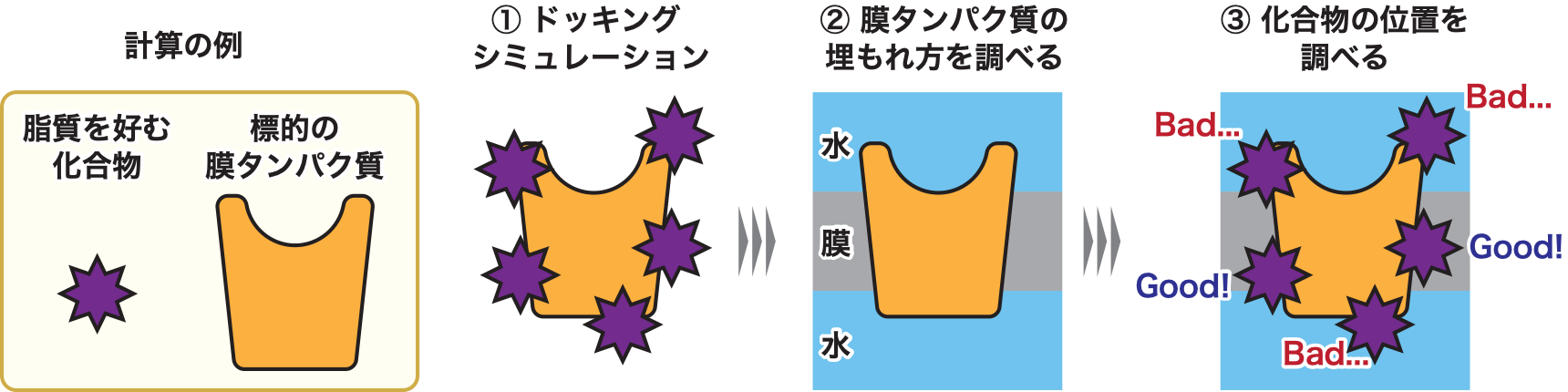
Scientists perform computational simulations for biological molecules detected in meteorites to clarify the origin of life on Earth.
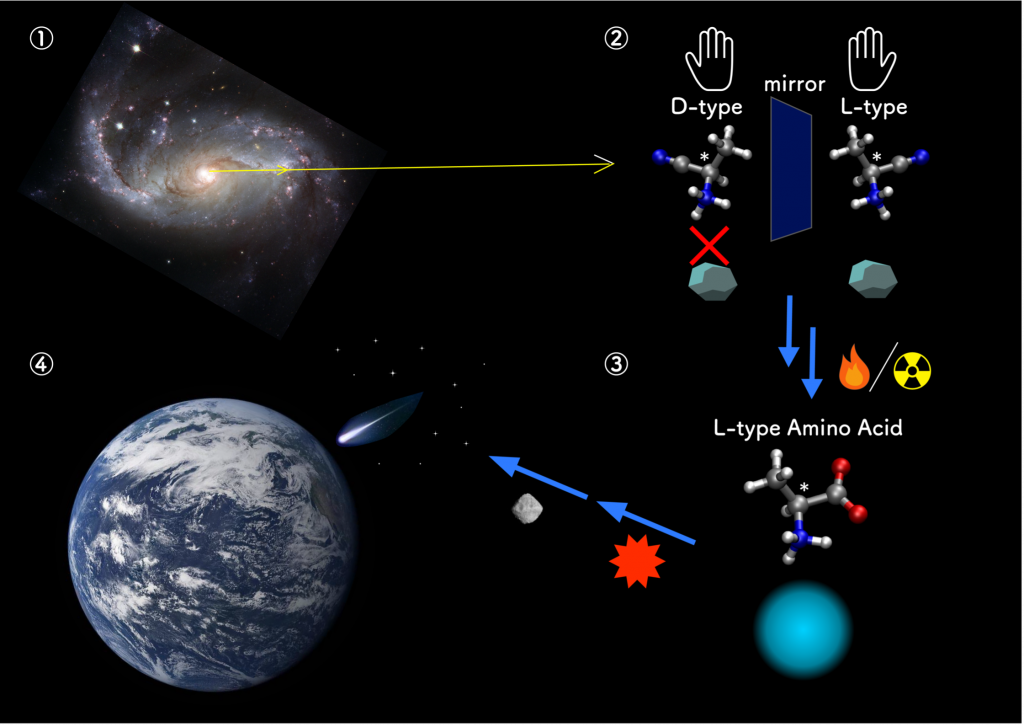
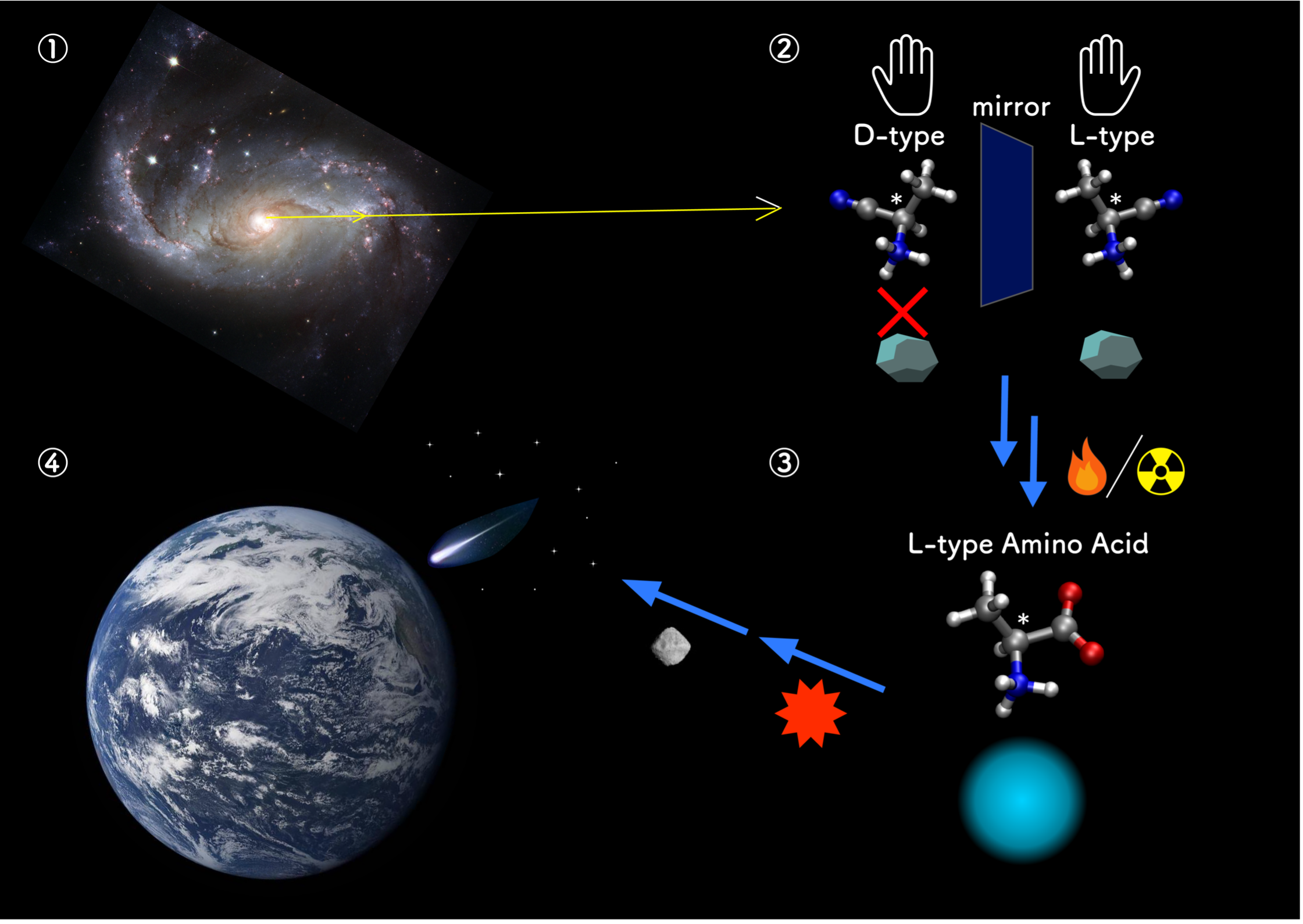
All biological amino acids on Earth appear exclusively in their left-handed form, but the reason underlying this observation is elusive. Recently, scientists from Japan uncovered new clues about the cosmic origin of this asymmetry. Based on the optical properties of amino acids found on the Murchison meteorite, they conducted physics-based simulations, revealing that the precursors to the biological amino acids may have determined the amino acid chirality during the early phase of galactic evolution.
If you look at your hands, you will notice that they are mirror images of each other. However, no matter how hard you try to flip and rotate one hand, you will never be able to superimpose it perfectly over the other. Many molecules have a similar property called “chirality,” which means that the “left-handed” (L) version of a molecule cannot be superimposed onto its “right-handed” (D) mirror image version. Even though both versions of a chiral molecule, called “enantiomers,” have the same chemical formula, the way they interact with other molecules, especially with other chiral molecules, can vary immensely.
Interestingly, one of the many mysteries surrounding the origin of life as we know it has to do with chirality. It turns out that biological amino acids (AAs)—the building blocks of proteins—on Earth appear only in one of their two possible enantiomeric forms, namely the L-form. However, if you synthesize AAs artificially, both L and D forms are produced in equal amounts. This suggests that, at some early point in the past, L-AAs must have come to dominate a hetero-chiral world. This phenomenon is known as “chiral symmetry breaking.”
Against this backdrop, a research team led by Assistant Professor Mitsuo Shoji from University of Tsukuba, Japan, conducted a study aimed at solving this mystery. As explained in their paper published in The Journal of Physical Chemistry Letters, the team sought to find evidence supporting the cosmic origin of the homochirality of AAs on Earth, as well as iron out some inconsistencies and contradictions in our previous understanding.
“The idea that homochirality may have originated in space was suggested after AAs were found in the Murchison meteorite that fell in Australia in 1969,” explains Dr. Shoji. Curiously enough, in the samples obtained from this meteorite, each of the L-enantiomers was more prevalent than its D-enantiomer counterpart. One popular explanation for this suggests that the asymmetry was induced by ultraviolet circularly polarized light (CPL) in the star-forming regions of our galaxy. Scientists verified that this type of radiation can, indeed, induce asymmetric photochemical reactions that, given enough time, would favor the production of L-AAs over D-AAs. However, the absorption properties of the AA isovaline are opposite to those of the other AAs, meaning that the UV-based explanation alone is either insufficient or incorrect.
Against this backdrop, Dr. Shoji’s team pursued an alternate hypothesis. Instead of far-UV radiation, they hypothesized that the chiral asymmetry was, in fact, induced specifically by the CP Lyman-α (Lyα) emission line, a spectral line of hydrogen atom that permeated the early Milky Way. Moreover, instead of focusing only on photoreactions in AAs, the researchers investigated the possibility of the chiral asymmetry starting in the precursors to the AAs, namely amino propanals (APs) and amino nitriles (ANs).
Through quantum mechanical calculations, the team analyzed Lyα-induced reactions for producing AAs along the chemical pathway adopted in Strecker synthesis. They then noted the ratios of L- to D-enantiomers of AAs, APs, and ANs at each step of the process.
The results showed that L-enantiomers of ANs are preferentially formed under right-handed CP (R-CP) Lyα irradiation, with their enantiomeric ratios matching those for the corresponding AAs. “Taken together, our findings suggest that ANs underlie the origin of the homochirality,” remarks Dr. Shoji. “More specifically, irradiating AN precursors with R-CP Lyα radiation lead to a higher ratio of L-enantiomers. The subsequent predominance of L-AAs is possible via reactions induced by water molecules and heat.”
The study thus brings us one step closer to understanding the complex history of our own biochemistry. The team emphasizes that more studies focused on ANs need to be conducted on future samples from asteroids and comets to validate their findings. “Further analyses and theoretical investigations of ANs and other prebiotic molecules related to sugars and nucleobases will provide new insights into the chemical evolution of molecules and, in turn, the origin of life,” concludes an optimistic Dr. Shoji.
Be sure to stay tuned as scientists continue to piece together this one grand puzzle called life!
###
This study has been supported by research projects (1) JST, PRESTO grant number JPMJPR19G6, Japan, and (2) JSPS KAKENHI grant numbers 19H00697, 20H05453, 20H05088, 22H00347, and 22H04916. Computational resources were partially supported by Multidisciplinary Cooperative Research Program in CCS, University of Tsukuba. The authors also thank the HPC Center at the University of Strasbourg funded by the Equipex Equip@Meso project and the CPER Alsacalcul/Big Data and the Grand Equipement National de Calcul Intensif (GENCI) under allocations DARI A0120906092 and A0140906092.
Original Paper
- Title of original paper:
- Enantiomeric Excesses of Aminonitrile Precursors Determine the Homochirality of Amino Acids
- Journal:
- The Journal of Physical Chemistry Letters
- DOI:
- 10.1021/acs.jpclett.2c03862
Correspondence
Assistant Professor SHOJI Mitsuo
Center for Computational Sciences (CCS), University of Tsukuba
2023.03.28











![[ウェブリリース]膜タンパク質に対して創薬シミュレーションを可能にする計算手法を開発](https://www.ccs.tsukuba.ac.jp/wp-content/uploads/sites/14/230322fig2-825x430.png)