Today, computational science is an indispensable research methodology in the basic and applied sciences and contributes significantly to the progress of a wide variety of scientific research fields. For multidisciplinary computational science based on the fusion of computational and computer sciences, frequent/regular opportunities for communication and collaboration are essential. The Center for Computational Sciences (CCS) at the University of Tsukuba aims to improve such collaborations between different research fields. In this symposium, plenary speakers in various fields of computational sciences will give us talks on research frontiers, comprehensible to researchers and graduate students in other fields. In 2010, the CCS was recognized under the Advanced Interdisciplinary Computational Science Collaboration Initiative (AISCI) by MEXT, and has since provided the use of its computational facilities to researchers nationwide as part of the Multidisciplinary Cooperative Research Program (MCRP).
Date and Venue
Dates: 2 Oct. [Mon] 14:00 - 3 Oct. [Tue] 17:00 Venue: EpochalTsukuba International Congress Center “Hall 300” *Zoom streaming will also be available, but no questions will be accepted online.
Program
Oct. 2 (mon)
14:00 – 14:15
Welcome address
SHIGETA Yasuteru
University of Tsukuba (Vice President and Executive Director for Research)
Welcome address
BOKU Taisuke
University of Tsukuba
14:15 – 14:45
Statistical Mechanics Analysis for Biomolecular Functions
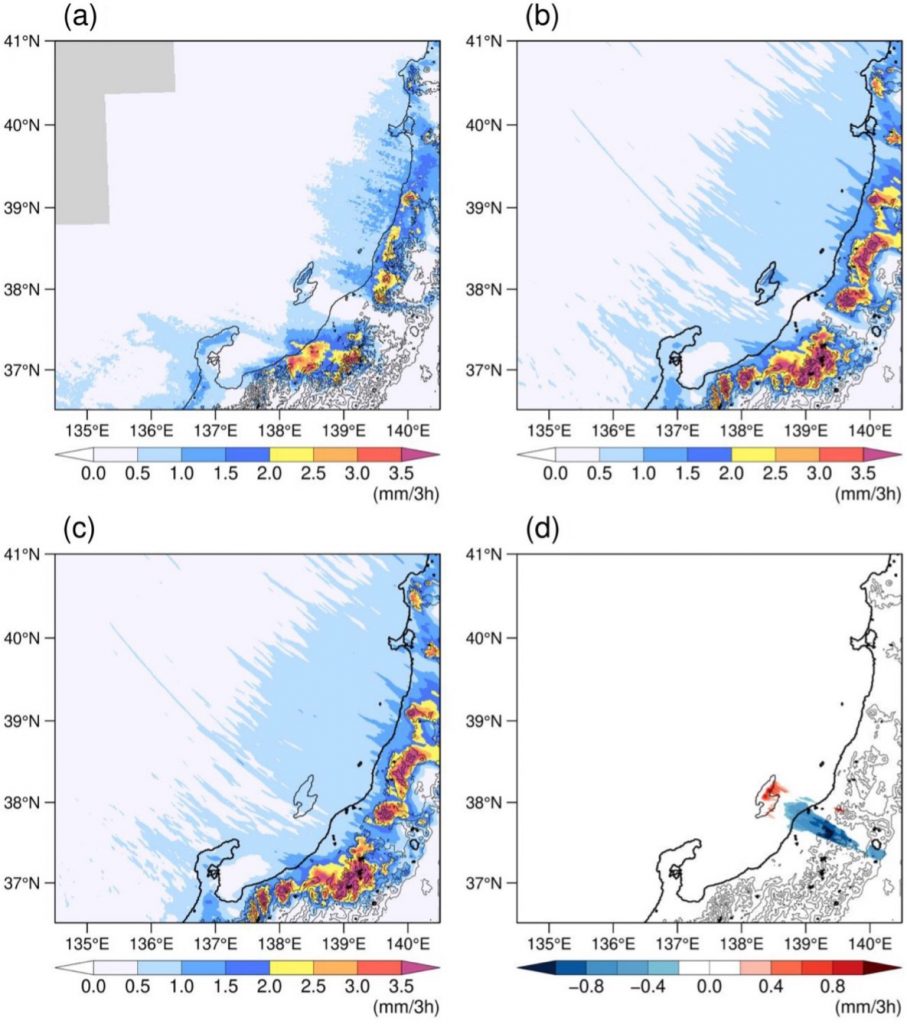
題名:The snow-shadow effect of Sado Island on Niigata City and the coastal plain 著者名:Hiroyuki Kusaka, Nobuyasu Suzuki, Masato Yabe, Hiroki Kobayashi 掲載誌:Atmospheric Science Letters 掲載日:2023年7月20日(ウェブ版) DOI: https://rmets.onlinelibrary.wiley.com/doi/10.1002/asl.1182
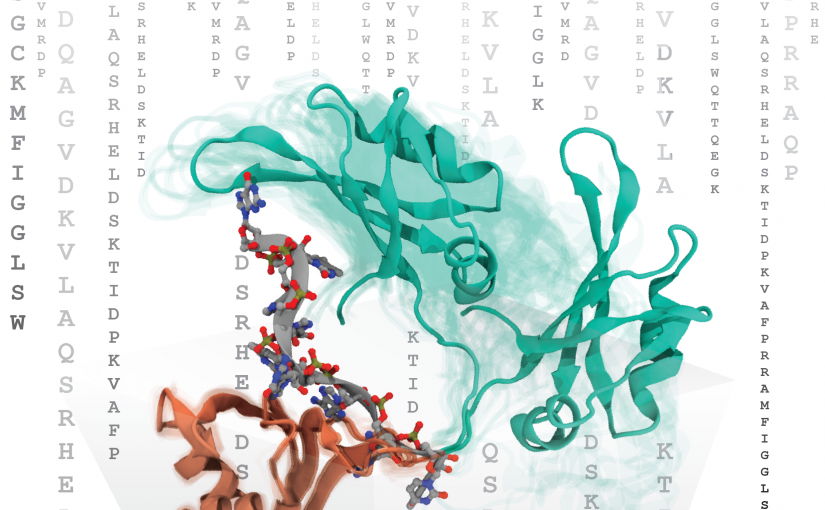
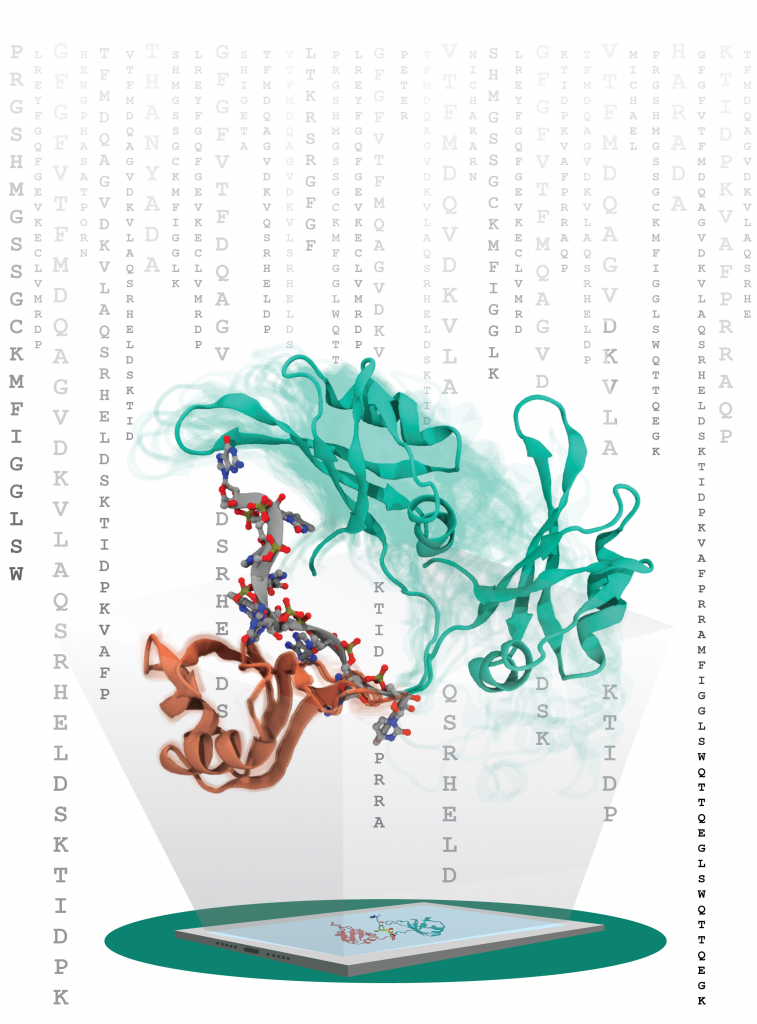
【題 名】 Determination of the Association between Mesotrione Sensitivity and Conformational Change of 4-Hydroxyphenylpyruvate Dioxygenase via Free-Energy Analyses 【著者名】 Yohei Munei, Kowit Hengphasatporn, Yuta Hori, Ryuhei Harada, Yasuteru Shigeta 【掲載誌】 Journal of Agricultural and Food Chemistry 【掲載日】 2023年6月5日 【DOI】 DOI: 10.1021/acs.jafc.3c01253 (https://pubs.acs.org/doi/10.1021/acs.jafc.3c01253)
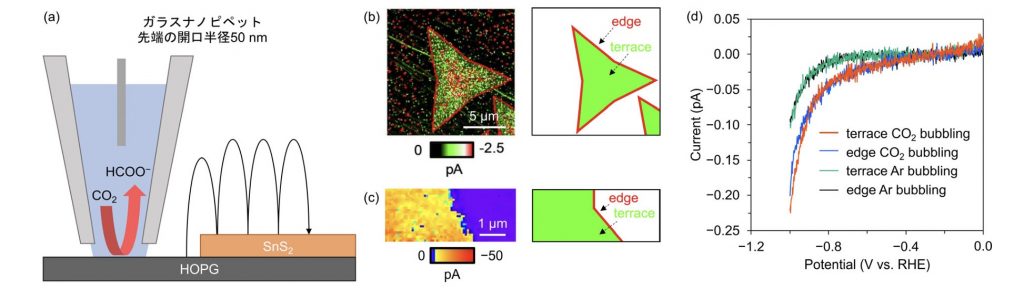
計算科学研究センターに在籍していた研究者らが中心となって開発したソフトウェア「SALMON(Scalable Ab-initio Light-Matter simulator for Optics and Nanoscience; https://salmon-tddft.jp/)」が、HPCIソフトウェア賞開発部門賞において奨励賞を受賞し、令和5年5月19日(金)に授賞式(オンライン)が行われました。
Prof. Masayuki Umemura (formerly of the Department of Astrophysics) and Prof. Hiroshi L. Tanaka (formerly of the Department of Environmental Science), who retired in March 2023, have been named Professor Emeritus of the University of Tsukuba.
Professor Emeritus Umemura (left) and Professor Emeritus Tanaka (right).
Affiliation: Division of Life Science, Center for Computational Sciences, University of Tsukuba
Field of Expertise: Computational chemistry including materials informatics, quantum chemistry, and molecular simulations.
Research: In our center, we seek a fixed-term assistant professor to develop computational methods using materials informatics (MI), classical molecular dynamics (MD) simulations, quantum chemical (QC) calculations, and/or apply it to actual problems in the field of the grant-in-aid for Transformative Research Areas “Mesohierarchy”. The successful candidate will be a member of the Divisions of Life Science. He/She will collaborate with experimental researchers in the field of Mesohierarchy. Based on the candidates’ expertise, he/she can teach in the faculty of physics, chemistry, or biology.
Starting date: October 1st, 2023 or later, as soon as possible
Period: Until September 30th, 2026 (After evaluation, he/she can extend it until March 31st, 2027)
Requirement: Applicants must have a doctoral degree or equivalent expertise.
Compensation ・Salary: Annual salary system (The annual salary will be determined based on the regulations of the University, taking into account the career of the employee.) ・Working hours: Discretionary labor system ・Holidays: Saturdays, Sundays, national holidays, New Year’s holidays (Dec.29 Jan. 3), and holidays determined by the University.
Submissions 1) Resume/CV (with photograph) 2) List of research activities including peer-reviewed papers, peer-reviewed proceedings, oral presentations at international conferences, competitive research funds (representative), awards, and so on. 3) Up to five major papers (at least four of which were published within the last five years) 4) Summary of research to date (within 1 sheet of A4 paper) 5) Research and education proposal (within 1 sheet of A4 paper) 6) A list of grants 7) A recommendation letter or the name of one professor, who is a reference for the applicant, with complete contact information 8) A document for Self-declaration on Specific Categories (*) 9) A document for Consent to Processing and Extraterritorial Transfer of Personal Data under GDPR (*) (EU General Data Protection Regulation) (Only the applicants located in the countries where belong to the European Economic Area or in the United Kingdom of Great Britain and Northern Ireland should submit the consent form). *All of the standardized forms can be downloaded from the following link: https://www.ccs.tsukuba.ac.jp/reqdocuments/
Submission deadline: Wednesday, May 31th, 2023 (JST). Please write “Application for Assistant Professor Position in Computational Medical Science (Mesohierarchy)” on the subject and send a zip file with a password for the documents (1-6) in the pdf format via e-mail to apply_2023_L02 [at]ccs.tsukuba.ac.jp ([at] should be replaced by @). The password should be separately sent to shigeta[at]ccs.tsukuba.ac.jp ([at] should be replaced by @ as well).
Miscellaneous: The Center for Computational Sciences has been approved as a Joint Collaborative Research Center by the Ministry of Education, Culture, Sports, Science, and Technology. We promote interdisciplinary computational sciences, including joint use of our supercomputer systems. The University of Tsukuba conducts its personnel selection process in compliance with the Equal Employment Opportunity Act.