 CCS Reports! 第二弾の後編は、ドイツ・フランクフルトで開催されたISC High Performance(2016年6月19日〜23日)の中の1セッション、HPC in Asia (ハイパフォーマンス・コンピューティング in アジア)にて、ポスター発表を行ったお二人の研究内容を紹介します。それぞれ、CCSで実際に動いている2台のスーパーコンピュータ、HA-PACS/TCAとCOMAに関する研究です。さっそく、スパコン研究の世界を覗いてみましょう! (2016.7.19)
CCS Reports! 第二弾の後編は、ドイツ・フランクフルトで開催されたISC High Performance(2016年6月19日〜23日)の中の1セッション、HPC in Asia (ハイパフォーマンス・コンピューティング in アジア)にて、ポスター発表を行ったお二人の研究内容を紹介します。それぞれ、CCSで実際に動いている2台のスーパーコンピュータ、HA-PACS/TCAとCOMAに関する研究です。さっそく、スパコン研究の世界を覗いてみましょう! (2016.7.19)
GPU間の直接通信で計算性能をあげる [HA-PACS/TCA]
ISC (International Supercomputing Conference) は、スーパーコンピュータ(スパコン)とスパコンを使った計算科学の国際学会で、毎年決まって6月にヨーロッパで開催されます(2015年は7月開催)。
計算科学研究センターは、東京大学情報基盤センターと共同運営する「最先端共同HPC基盤施設:JCAHPC」としてブースを出展し、今年稼働を開始するスーパーコンピュータOakforest-PACS(OFP)の紹介を行いました。(詳しくは「ISH High Performance 参加報告(前編)」をご覧ください。)
HPC in Asia (ハイパフォーマンス・コンピューティング in アジア)はISCの1セッションとして、アジアで行われているスパコン研究を世界の人々に紹介し、情報交換を行うことを目的に6月22日に開催されました。

HPC in Asia でポスター発表をした研究者へのミニインタビュー。まず一人目は、高性能計算システム研究部門の藤田典久研究員です。
藤田さんは、GPU*1間を直接通信する技術によって、具体的なアプリケーションの性能がどれだけ上がるのかを研究しています。
近年のスーパーコンピュータでは、計算性能向上のための1つの方法として、演算加速装置*2を持つものが増えています。演算加速装置を使うことで、CPUよりも高速で演算処理(計算)をすることができます。しかし、従来の環境では、演算加速装置(例えばGPU)のデータを他のノード*3に送るには、一度CPUを経由しなくてはならず、GPUからCPU、CPUから別のノードのCPU、そしてまたCPUからGPU・・・というようにデータ転送の回数が多くなってしまいます。通信が多いと、それだけ全体の計算に掛かる速度が遅くなってしまう・・・つまりは計算性能が落ちてしまう、ということ。
*1 GPU:Graphics Processing Unitの略。本来PCサーバにおけるグラフィックス処理を目的として作られた専用プロセッサだが、近年はその高い演算性能を利用した高性能計算への転用が活発化している。
*2 演算加速装置:汎用計算を行うCPUに対する拡張機構として、PCI Expressなどの汎用バスを介して接続される高性能演算装置。計算を自律的に行うことは不可能で、CPUから起動されることにより、アプリケーションの一部または全部を高速に実行する。一般的に利用可能な演算加速装置の例としては、GPUやメニーコアプロセッサなどがある。
*3 ノード:現在のスーパーコンピュータは、たくさんのコンピュータを高速ネットワークで繋いだ”並列型“が主流。1ノードが1コンピュータに相当。
計算を早くする演算加速装置なのに、通信のせいで全体性能が下がってしまったら、困るじゃないですか、藤田さん。
「計算科学研究センターでは、この問題への一つの解決策として、TCA(Tightly Coupled Accelerators) というコンセプトを提唱しています。TCAというのは、GPUとかメニーコアプロセッサといった演算加速装置の間を直接通信することによって、計算全体の性能をあげようという考え方です」
 [HA-PACS/TCA]
[HA-PACS/TCA]
計算科学研究センターのスーパーコンピュータ「HA-PACS/TCA」のTCAですね。
センターの見学で公開しているので、これを読んでいる人の中にも、「HA-PACS/TCA」を実際に見たことがある人もいるのではないでしょうか。藤田さんによると、「HA-PACS/TCA」の「TCA」部分は、この演算加速装置同士を直接通信させるというコンセプトの実験用環境として作られたもので、GPU同士の直接通信を可能にするPEACH2という機構が組み込まれています。1つのノードに、GPU間の直接通信をするPEACH2と従来型の通信をするInfiniBandネットワークという機構が対称になるように配置されているため、両者の比較をほぼ同じ状態でできるのが特徴なのだとか。この実験環境を使って、今回のポスター発表の研究も行われています。
PEACH2と従来型ネットワークのそれぞれで、異なるノードにあるGPU間の通信時間を比較したのがポスター左下のグラフです。縦軸が時間・横軸が送るデータの大きさで、時間が短い(縦軸の下の方)ほど、性能がいいことを示しています。グラフを見ると、PEACH2(青い線)の方が従来型(赤い線)よりも常に短い時間でデータを送っていますね。例えば、8Byteのデータを送った際には、PEACH2では2マイクロ秒(青い折れ線)、従来型通信だと4マイクロ秒(赤い折れ線)の時間がかかっていて、その差は約2倍。
「昔はもっと差があったんですけど、従来型のInfiniBandは製品として作られているので、どんどん新しい技術が使えて、徐々に追いつかれてきつつあるんです。でもまだ、PEACH2の優位面はあるな、と」
さすが日進月歩の世界。3年くらい前(「HA-PACS/TCA」の稼働は2013年)は、もう“昔”なんですね・・・。
左側の下から二番目のグラフでは、縦軸が一秒間にどれだけのデータを送れるか・横軸がデータの大きさで、上に行くほど性能がいいことになっているんですが、右の方に行くとPEACHI2(青い線)が従来型(赤い線)に負けちゃってます。これはなんですか?
「PEACH2にも苦しいところがあって、PEACH2はピークのバンド幅(1秒間に通信できるデータ量)が低いんです。1コネクションあたりのバンド幅が最大で4GB/s。対して、従来型のInfiniBandはだいたい倍の8GB/s。なので、メッセージ長を大きくしていくと、ピークのバンド幅が足りないのでPEACH2が負けてしまう、と。」
一度に送れるデータの量はPEACH2の方が少ないから、あまりデータが大きくなるとPEACH2の方が遅くなってしまうんですね。
「ただ・・・あ、ウィーク・スケーリングとストロング・スケーリングってわかりますか?」
わかりません! と正直に答えたら、クスッと笑われてしまいました・・・。藤田さんに教えていただいたので、図を入れて解説します。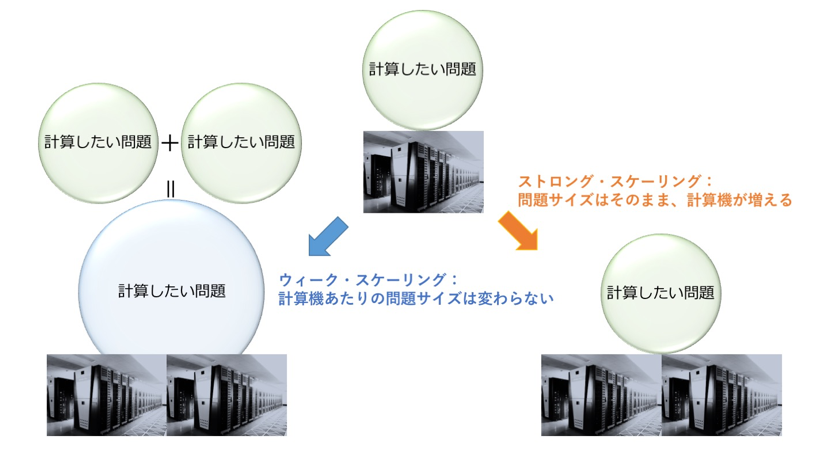
ウィーク・スケーリングとは、1計算機にとっての計算の量(仕事量)はそのままに、計算機と問題サイズを大きくするもの。問題サイズはそのままに、計算機だけを増やすのがストロング・スケーリングです。
普通、計算機が2倍、問題サイズも2倍なら、性能は最初と変わらないように思いますよね? また、問題サイズをそのままに計算機を2倍にしたら、計算性能は2倍速くなりそうな気がします。ところが、そう簡単にいくことはまずないのだとか。
というのも、ただ計算機を増やすだけでは減らない“固定費”があるからなんです。固定費の例として藤田さんがあげたのは、やはり通信。例えばPEACH2では、8Byteのデータを送っても16Byteのデータを送っても、かかる時間は2マイクロ秒で同じ。この2マイクロ秒は、削ることのできない固定費、というわけです。
「一般的なアプリケーションでは、ストロング・スケーリングによって計算機あたりの仕事量が減ると、1通信あたりのデータサイズも減っていくので、PEACH2の「小さいデータを速く送る」特性が有利になってきます。今後はエクサスケール*4の計算機に向けて、ストロング・スケーリングできちんと性能を出すことが重要になりつつあるので、そこにPEACH2の存在意義があると思っています。」
藤田さん、ありがとうございました!
*4 エクサスケール:1秒間にエクサ(10の18乗)回の計算ができるような規模のスーパーコンピュータ。実現が期待されている。現在、世界で最も早いスーパーコンピュータ「神威 太湖之光」は93ペタフロップス(1秒間に93×10の13乗回の浮動小数演算ができる性能)をもつ。
次世代スパコンの主流?! メニーコアプロセッサを使い倒す [COMA]
インタビュー二人目は、高性能計算システム研究部門の朴教授のもとで研究を進めている、博士後期課程1年の廣川祐太さんです。
廣川さんは、原子核物理部門の矢花教授との共同研究で、電子ダイナミクスの第一原理計算をするアプリケーションARTED(アーテッド)を、メニーコアプロセッサ*5を搭載したシステムに最適化するためには何が必要か? というテーマで研究をしています。
*5 メニーコアプロセッサ: 従来の汎用マルチコアCPUが1つのチップ上に10個程度のCPUコアを搭載していたのに対し、数十個(COMAに搭載されているインテルXeon Phiコプロセッサでは61個)のCPUコアを搭載する新世代の演算加速型プロセッサ。性能を引き出すにはプログラミングに様々な工夫が必要とされる。
廣川さんの研究では、計算科学研究センターのスーパーコンピュータCOMAが使われています。COMAはCPUの他に、演算加速装置としてメニーコアプロセッサを搭載しているという特徴があります。CPUだけを使うこともできるし、演算加速装置を一緒に使うこともできる、という柔軟な使い方をされているCOMA。でも、廣川さんはそれでは「もったいない」といいます。
「COMAの性能が1ペタフロップス*6なのは、メニーコアプロセッサが840テラフロップス*6くらい、CPU側が160テラフロップスくらいあるためで、片方だけ使うとそれだけピーク性能がさがっちゃうんですよね。せっかくあるペタフロップス級の性能が全然出ない。」
*6 ペタフロップス・テラフロップス:計算機の処理性能の指標としてFLOPS(フロップス)があり、1秒間に何回の浮動小数点数演算ができるかを表す。ペタフロップス(Peta FLOPS)は1秒間に10の15乗回、テラフロップス(Tera FLOPS)は1秒間に10の12乗回の計算ができることを示す。

[COMA]
確かに、せっかく演算加速装置が搭載されているのだから、使わないともったいない気がします。けれど、廣川さんによると、2つのプロセッサ(CPUとメニーコアプロセッサ)の性質が違うので、どう一緒に使うかが難しいのだそう。二つの異なる性質をうまいこと使いこなして、一番性能がでる使い方をするにはどうしたらいいか? という研究が、今回の廣川さんのポスター発表です。
藤田さんの研究のように、2つのプロセッサ間の通信をどうするか? という研究だと思ったら、違うんですって。
「僕らのアプリケーション(ARTED)は、並列化が非常に簡単になっていて。通常、三次元の空間を格子状に分割すると分割面で通信が必要になるんですけど、このアプリケーションではそうした時間のかかる通信が非常にすくないんです。なので最初にやるべきことは、とにかく計算を速くすればいい。」
というわけで、第1段階は「とにかく計算を速くする」ための作業です。ARTEDのコード(プログラム)を、メニーコアプロセッサとCPUそれぞれの特性に合わせて修正します。コンパイラを使って自動でコードを修正する方法と、それをさらに手動で修正する方法によって、核となる計算を約8倍も速くすることができました。しかし、ここで次の問題が・・・。
アプリケーション全体の性能を評価する時、メニーコアプロセッサとCPUに単純に同じ量の仕事を割り当ててしまうと、両者の性能が違うために遅い方に引っ張られてしまうんです。
なので、第2段階は「一緒に始まって一緒に終わるような仕事の配分を見つけること」。例えば、メニーコアが速ければそちらにもう少し計算量を割り当てるというようにして、ちょうどよく一番性能が出そうな仕事の割り当てを見つけ、アプリケーション全体の性能評価をしたのだそう。結果は?
「全体性能としては、メニーコアプロセッサとCPUをバランス良く使うと、CPU単体よりも最大で2.16倍速い、という結果になりました。CPUだけを倍の数使うよりも、2つのプロセッサをまとめて使ったほうがまだ速いですよ、ということになります。」
今年稼働を開始するOakforest-PACS(OFP)も、京コンピュータの次世代機として開発がスタートしている日本の次世代スパコン:フラッグシップ2020(ポスト「京」コンピュータ)も、メニーコアプロセッサを搭載することが決まっています。スパコンが違っていても、メニーコアという仕組みを使う以上は共通する課題や似たような問題がでてくる、と廣川さんは言います。この研究のこれからの展開を伺うと、
「今のシステムだけではなくて、次世代で中心になるであろうメニーコアシステムに最適化するには、何が必要で何をしなくちゃいけないのか? という研究ですね。」
とのこと。先を見据えた研究ですね。今後の発展に期待してます!
廣川さん、ありがとうございました。


[写真:ポスターの説明をする藤田研究員と博士課程1年の廣川さん]
取材協力
- ・藤田典久(ふじた のりひさ)研究員
- ・廣川祐太(ひろかわ ゆうた)さん(博士課程1年)
合わせて「ISC High Performance 参加報告(前編)」もどうぞ。
関連リンク
・ISC2016
・最先端HPC基盤施設(JCAHPC)
・プレスリリース「最先端共同HPC基盤施設の活動を開始 筑波大学と東京大学によるスーパーコンピュータ共同開発、共同運営・管理」
・プレスリリース「最先端共同HPC基盤施設がスーパーコンピュータ システム(ピーク性能25PFLOPS)の導入を決定 ―次世代メニーコア型プロセッサを搭載―」