
塩川 浩昭 准教授
計算情報学研究部門 データ基盤分野
膨大な量のデータを扱うビッグデータ解析では、解析にかかる時間がネックになります。塩川准教授は、限られた計算資源でビッグデータ解析を実現するための研究を進めています。
(2020.6.8 公開)
「普通のPCでビッグデータ解析」への挑戦
大量のデータ(ビッグデータ)から有用な情報を引き出す技術。それが、ビッグデータ解析です。例えば、大量のSNS上の情報からユーザーが欲しいと感じているサービスを把握したり、無数の実験や観測のデータから共通の法則を見出したりと、ビジネスでも学術研究の場面でも、ビッグデータ解析は広く活用されています。あなたのスマホ画面に興味のある広告が表示されたら、それもビッグデータ解析の結果かもしれません。
こうしたビッグデータ解析では、より大量のデータを扱うことが重要です。しかし、データ量が増えるということは、解析にかかる計算の量が増えるということであり、計算にかかる時間が増えることにつながります。「知りたいのは明日の天気なのに、予報のための計算に一週間かかる」というのでは困りますよね。
この課題の解決には、より賢く計算することで計算の高速化を進めることが必要です。
また、計算の高速化だけでなく省メモリ化もできれば、スーパーコンピュータ(スパコン)のような高性能の計算機がなくても、ビッグデータ解析が可能になります。
塩川准教授の研究では、普通のパソコンのような限られた計算資源で、大規模なデータ解析ができるようにするための賢い計算方法(アルゴリズム)の開発を行っています。
データ内のモチーフのくり返しに着目
ビッグデータ解析の中でも、複数の点と点をつないだネットワークを分析して、関連の強いものをグループ化していくことを、グラフデータ分析といいます。
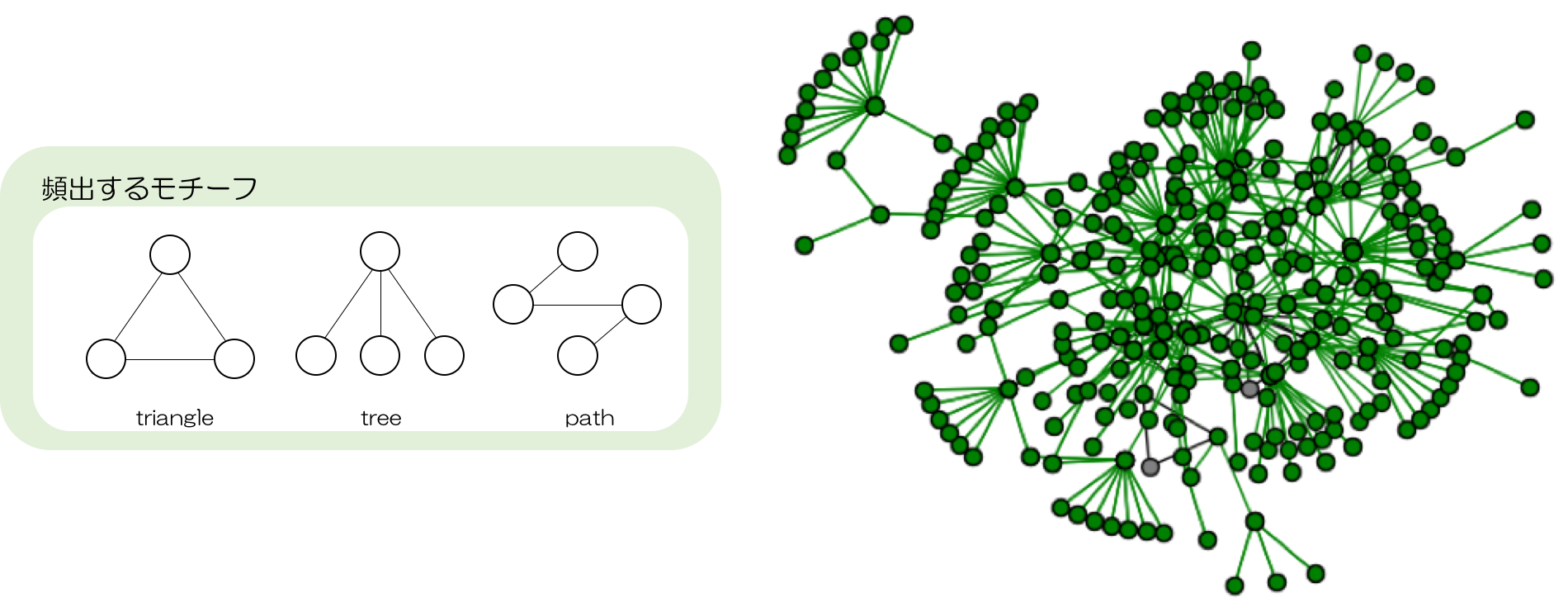
グラフデータ分析のアルゴリズムを賢くするために、塩川准教授の研究では、“データの中に同じモチーフ(基調構造)が繰り返し現れ、その出現頻度には偏りがある”という現象(Data Skewness)に着目しました。実際のデータは、一見複雑なネットワーク構造に見えても、triangle、tree、path、などの特定のモチーフが繰り返し現れています(図1)。これまでの方法では、こうした繰り返し部分も全て計算していましたが、同じ構造に同じ計算を繰り返していては時間がかかります。そこで、繰り返し構造が出てきたら一つの塊とみなして中まで細かく計算しない、というように余計な計算を減らし、本当に計算しなくてはいけないところに絞ったアルゴリズムを作ることで、精度を落とさずに計算を高速化することに成功しました。
新しく開発した方法では、デスクトップパソコンで30億件のTwitterデータを6.7秒で解析することに成功し、これまでの方法より約1,000倍の高速化を実現しました。計算が速くなったことで、これまでデスクトップパソコンでは計算できなかったようなデータ量を計算することも可能になりました。
ビッグデータ解析のアルゴリズムが高性能になることで、産業・医療・学術などさまざまな場面で、従来スパコンが必要だったような計算を誰もができるようになります。
例えば、たくさんのタンパク質を点、その相互作用を線とみなしたタンパク質相互作用ネットワークを分析することで、高効率に性質の似たタンパク質の探索ができるようになります。それによって、薬の候補や病気の原因となるタンパク質の探索が進み、創薬などの場面で活用されることが期待されます。こうした分析をより高効率にするために、塩川准教授の研究が役立てられています。
さらに詳しく知りたい人へ
- ACT-I成果発表会 (第2部に塩川先生の講演映像とポスターがあります)
- 基調構造を利用したグラフクラスタリングの高速化(和文論文)