Chief
 |
TATEBE Osamu, Professor, Osamu Tatebe received a Ph.D. degree in computer science (1997, Univ. of Tokyo). He worked at Electrotechnical Laboratory (ETL), and National Institute of Advanced Industrial Science and Technology (AIST) until 2006. He is now a professor of Center for Computational Sciences at University of Tsukuba. His research area is high-performance computing, data-intensive computing, and parallel and distributed system software. |
Overview
In order to respond to demands for cutting-edge, ultra high-speed, and large capacity computation resources for the computational sciences, the High Performance Computing Systems (HPCS) Division in the Center for Computational Science (CCS) is investigating a wide variety of HPC hardware and software systems. Through collaborative work with other application divisions in the Center, we are researching the creation of ideal HPC systems that are most suitable for application to real world problems.
Our research targets, which are spread across various HPC technologies, include high performance computing architecture, parallel programming language, massively parallel numerical algorithms and libraries, Graphics Processing Unit (GPU)-accelerated computing systems, large scale distributed storage systems, and grid/cloud technology. The following are among our more recent research topics.
Research topics
A multi-hybrid accelerated computing system
Graphics processing units (GPUs) have been widely used in high-performance computing (HPC) systems as accelerators by their extreme peak performance and high memory bandwidth. However, the GPU does not work well on applications that employ complicated algorithms using partially poor parallelism, much of conditional branches or frequent inter-node communication. To address this problem, we combine field-programmable gate arrays (FPGAs) with GPUs and make FPGAs not only cover GPU on non-suited computation but also perform high-speed communication. This system concept is called Accelerator in Switch (AiS) and we believe that it offers better strong scaling. Our brand-new supercomputer Cygnus incorporates this concept and it has been in operation since April 2019. In future, we will propose a next generation accelerated computing system by applying this concept to computational application and demonstrating its effectiveness.
 Fig.1 Prototype of AiS base system
Fig.1 Prototype of AiS base system
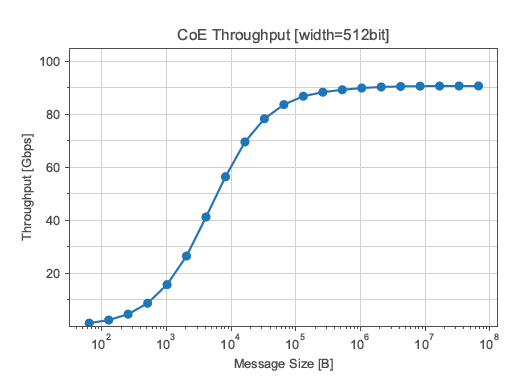
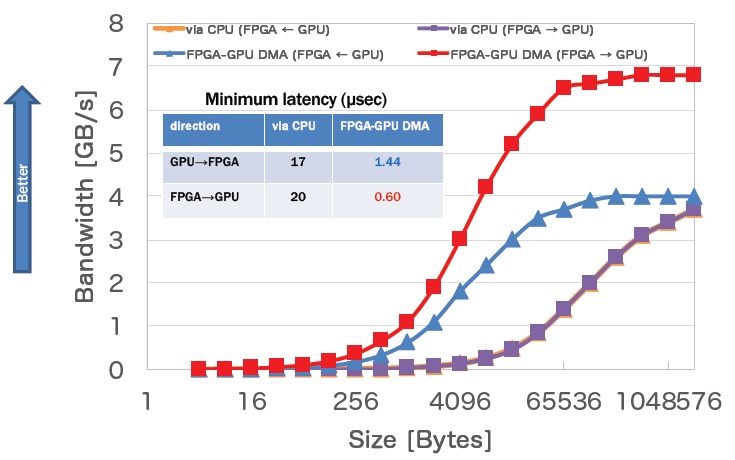
Fig.2 FPGA-to-FPGA communication performance on 100Gbps link (Left), GPU-FPGA communication performance with DMA transfer (Right)
XcalableMP
XcalableMP is a PGAS-base large scale parallel programming language. In future supercomputer generations, which are expected to have millions of cores and distributed memory architecture, traditional message passing programming would strongly reduce software productivity. To maintain high levels of performance tuning in large-scale parallel programming ease, we have designed and implemented a new language named XcalableMP. This language provides OpenMP-like directive base extension to C and Fortran to permit a global view model of data array handling in the manner of Partitioned Global Address Space (PGAS) concept as well as local-view modeling when describing highly tuned parallel programs. We are also developing an extension of XcalableMP for accelerating devices named XMP-dev in order to cover, for example, large-scale GPU clusters.
Gfarm
Gfarm is a large-scale wide area distributed file system. In order to utilize computing resources spread widely throughout the world, high performance large-scale shared file systems are essential to process distribution freedom. Gfarm is an open-source distributed file system developed in our division that has the capability to support thousands of distributed nodes, tens of petabytes of distributed storage capacity, and thousands of file handling operations per second. With carefully designed system construction to ensure the metadata servers do not cause performance bottlenecks, it also provides a large degree of scalability for client counts. Gfarm is officially adopted as the High Performance Computing Infrastructure (HPCI) shared file system and provides nationwide access to and from any supercomputer in Japan.
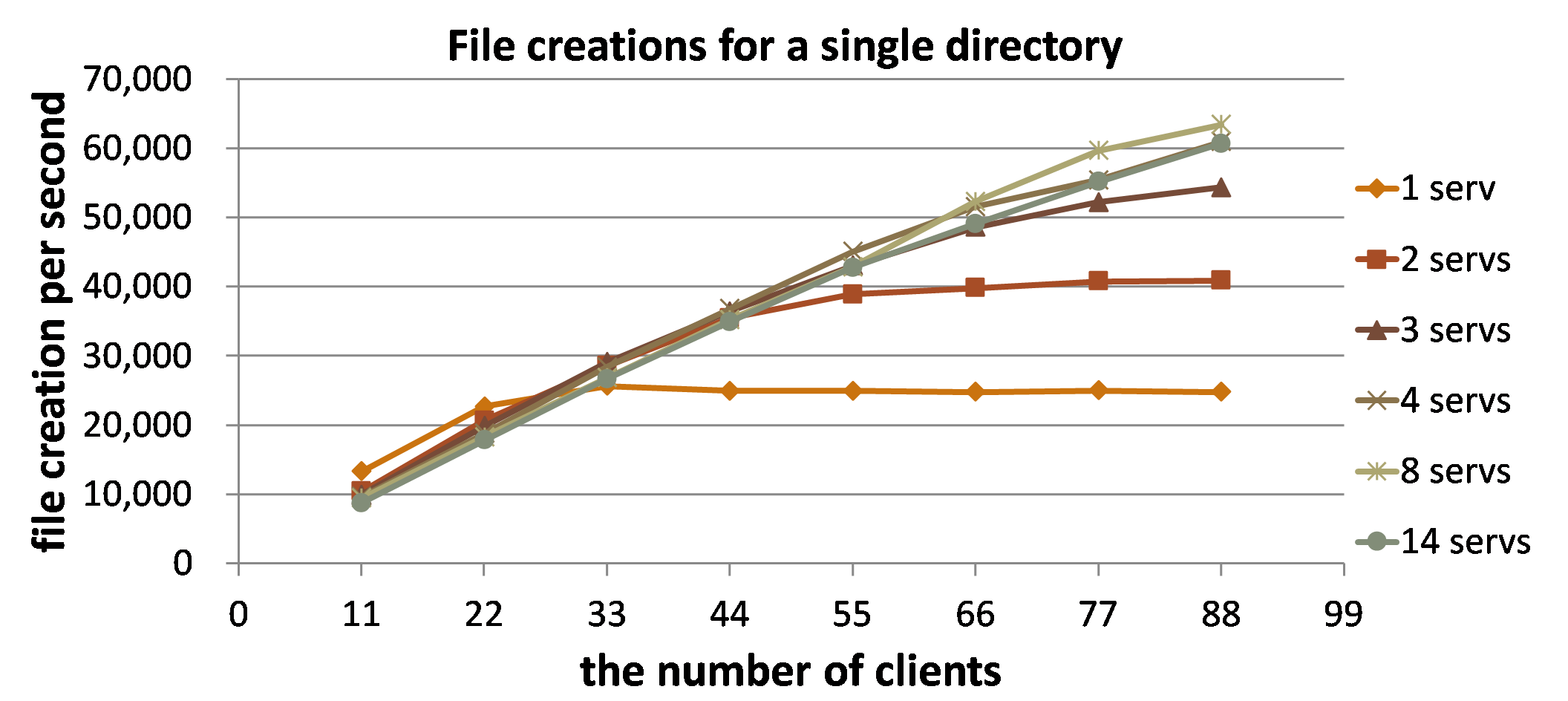
Fig.3 Meta-data server scalability of PPMDS
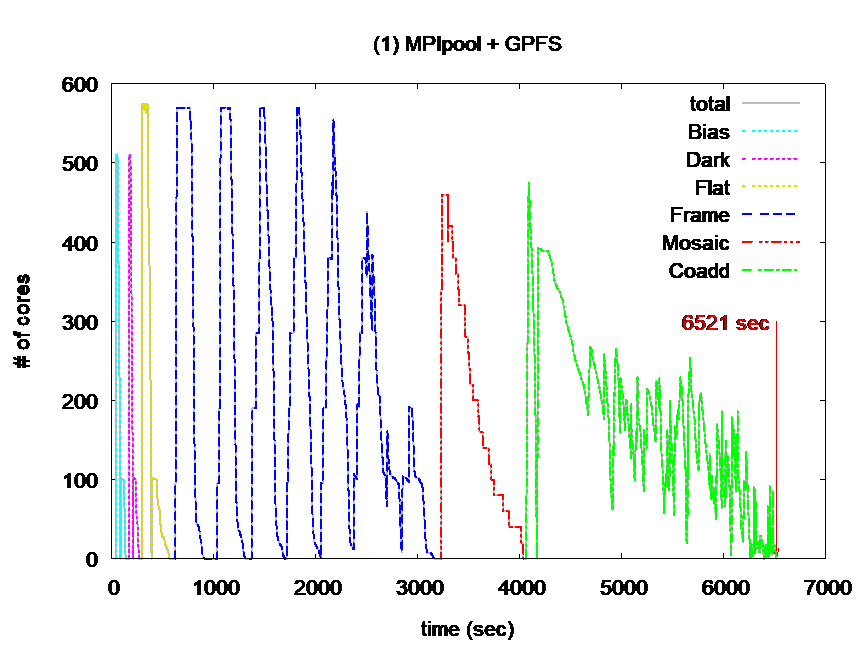
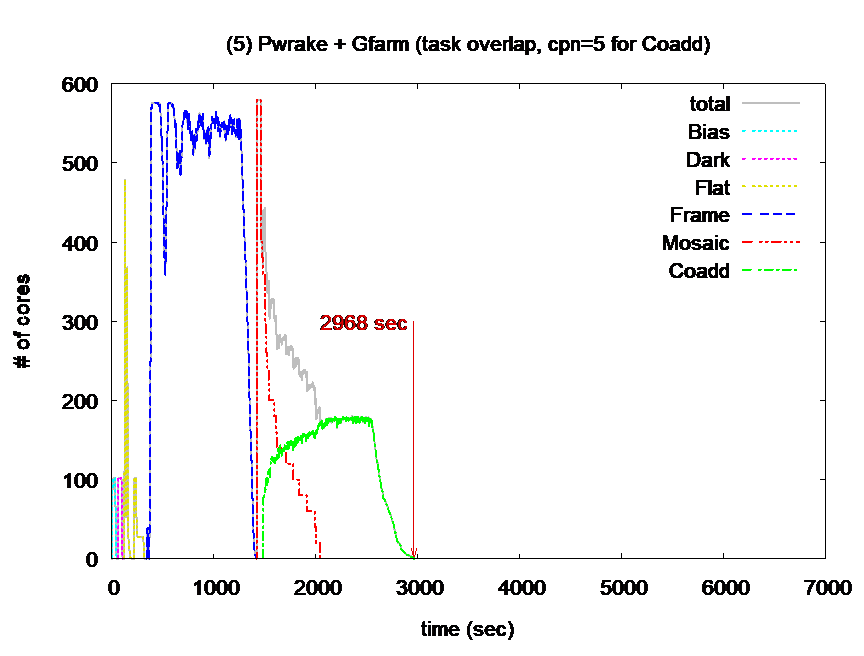
Fig.4 The number of running cores during workflow execution with 2 configurations (Left: Conventional method of GPFS, Right: Proposed method with Pwrake + Gfarm)
High performance and large scale parallel numerical algorithms
FFTE is an open-source high performance parallel fast Fourier transform (FFT) library developed in our division that provides an automatic tuning feature that is available from PC clusters to MPP systems. We are developing Block Krylov subspace methods for computing high accuracy approximate solutions of linear systems with multiple right-hand sides. The Block GWBiCGSTAB method developed in our division can generate high accuracy approximate solutions than the conventional methods.
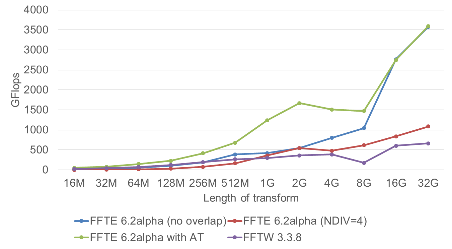
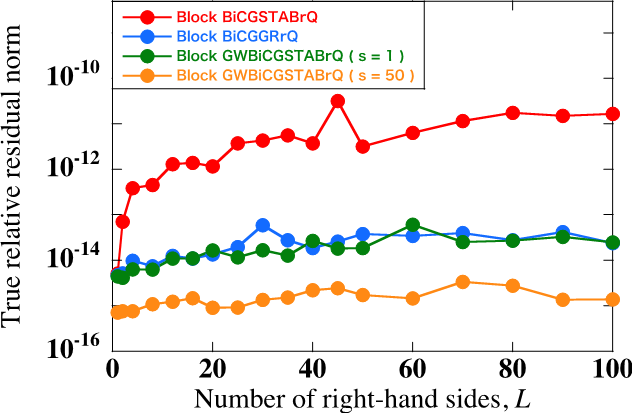
Fig. 5 Performance of parallel 1-D FFTs on Oakforest-PACS (1024 nodes) (Left). Comparison of the accuracy of the approximate solutions among three Block Krylov subspace methods (Right).
Web sites
High Performance Computing System Laboratory
(Update: 2019 Dec. 18)