Empirical Research for Exascale Computing
Head: BOKU Taisuke
The theoretical peak performance of massively parallel supercomputers is represented as the processor performance of a single node and the number of those nodes. The performance improvement of supercomputers, to date, has been mainly achieved by the “scaling system”, which refers to increasing the number of computing elements in a system. However, faced with limitations related to electric power consumption and/or the thermal or fault ratio of each part, “weak-scaling” strategies are facing their achievable limits. To overcome these limitations, it will be necessary for the next generation of Exascale computing to improve the single node performance by several tens to hundred TFlops, as well as to establish fault tolerant technology that will enable several million nodes to be incorporated into a system. For the single node performance improvements, one of the most promised methods is using accelerators to reduce the time-to-solution, rather than enlarging the computation problem size. This is known as the “strong-scaling” problem.
In the Project Office for Exascale Computing System Development, we have been researching the next generation of accelerated computing systems under the new concept of accelerated computing named Accelerator in Switch (AiS) and Multi-Hybrid Accelerated Supercomputing. Currently, the main player of accelerated supercomputing is Graphics Processing Unit (GPU) to be represented as a number of top-ranked systems in TOP500 List. However, GPU is not a perfect solution to apply to all fields of application although it provides the highest theoretical peak performance, high memory bandwidth and high performance/power ratio. Since the GPU performance comes from its very high degree of Single Instruction and Multiple Data (SIMD) type parallelism in the instruction level, some categories of applications to imply (partially) low degree of parallelism, frequent conditional branch and inter-node communication are not suitable for acceleration only by GPUs. AiS is a new concept through our collaborative researches under codesigning among multiple application fields and HPC research over multiple institutes, to introduce new technology for HPC to employ Field Programmable Gate Array (FPGA) additionally to GPUs.
Under the concept of AiS, we introduced the first platform as the proof-of-concept system named Cygnus as the prototype of 10th generation of PAX/PACS series supercomputer at the CCS (see “Supercomputers“).
Each node of Cygnus system consists of multiple GPUs and FPGAs to exploit high sustained performance on various applications which are not suitable for GPU-only solution.
To realize the concept of AiS and show the performance of our solution, we have been developing elementary system parts such as high speed interconnection between FPGAs over nodes, GPU-FPGA fast data transfer, and programming environment for such a complicated multi-device system. Since FPGA is not an ordinary “software programmable” device, specially designed modules are required with various programming tools such as Verilog HDL or OpenCL.
High speed inter-node communication
In our project office, we previously developed the original inter-GPU communication system named Tightly Coupled Accelerators (TCA) by FPGA to provide an external PCI-Express communication hub (PEACH: PCI-Express Adaptive Communication Hub) for high-speed direct data transfer between GPUs over nodes. However, the latest high-end FPGAs are equipped with their own optical communication link up to 100Gbps of performance. We use this feature for high-level parallel programming on multiple FPGAs over nodes by originally developed communication layer. It is provided as Verilog HDL modules which can be invoked from user level OpenCL code as like as ordinary communication library. We achieved very high speed and low latency communication on the user level OpenCL code.
GPU-FPGA DMA
In the concept of AiS, we combine GPU computing for absolute floating operation power and FPGA for flexible computation and high performance communication. To combine these devices, it is required to establish high-speed data transfer among them within a node. We developed GPU-FPGA Direct Memory Access (DMA) module which can be called from user-level OpenCL. It realizes very low latency communication over PCI-Express without redundant data copy through the host CPU memory and provides easy programming method for users on OpenCL level.
PPX (Pre-PACS-X)
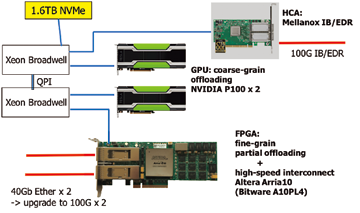
Before installation of Cygnus, the CCS constructed a testbed system of PACS-X Project named Pre-PACS-X (PPX). It is a mini-cluster system with 13 computation nodes where each node consists of two Intel Xeon CPU sockets, two NVIDIA GPU (Tesla V100 or P100) and an Intel FPGA board (Arria10) from 2016. On this testbed, we have been developing all the modules to implement AiS concept and production system resulted to Cygnus supercomputer. Each node is also equipped with 1.6 TByte of NVMe as local storage and testbed for network accessible storage device through 100Gbps of InfiniBand EDR. On PPX, inter-FPGA network speed is 40Gbps by Arria10 and all nodes are connected by 100Gbps Ethernet switch. On productive Cygnus system, we introduced a 2-D Torus network without switches between 64 of FPGAs (two FPGAs per node on 32 nodes) by 8×8 configuration. PPX is also used for application development to utilize GPU and FPGA together under AiS concept.

(Update: May. 7, 2021)